用 rustc 源码实现拼写错误候选词建议
作者: 吴翱翔@pymongo / 后期编辑:张汉东
最近想给一个聊天应用的聊天消息输入框加上拼写错误检查,毕竟 word, keynote 等涉及文本输入的软件都有拼写错误检查和纠错功能
于是想到开发中经常用的 rustup, cargo, rustc 不就内置了拼写错误时纠错建议的功能么?
在 rustup 输入错误的单词时例如 rustup dog,此时 rustup 就会提示把 dog 改成 doc
[w@w-manjaro ~]$ rustup dog
error: The subcommand 'dog' wasn't recognized
Did you mean 'doc'?
字符串的编辑距离
rustup 的拼写纠错建议的实现
以 Did you mean 的关键词全文搜索 rustup 源码,找到出处在 src/cli/error.rs
#![allow(unused)] fn main() { fn maybe_suggest_toolchain(bad_name: &str) -> String { let bad_name = &bad_name.to_ascii_lowercase(); static VALID_CHANNELS: &[&str] = &["stable", "beta", "nightly"]; lazy_static! { static ref NUMBERED: Regex = Regex::new(r"^\d+\.\d+$").unwrap(); } if NUMBERED.is_match(bad_name) { return format!( ". Toolchain numbers tend to have three parts, e.g. {}.0", bad_name ); } // Suggest only for very small differences // High number can result in inaccurate suggestions for short queries e.g. `rls` const MAX_DISTANCE: usize = 3; let mut scored: Vec<_> = VALID_CHANNELS .iter() .filter_map(|s| { let distance = damerau_levenshtein(bad_name, s); if distance <= MAX_DISTANCE { Some((distance, s)) } else { None } }) .collect(); scored.sort(); if scored.is_empty() { String::new() } else { format!(". Did you mean '{}'?", scored[0].1) } } }
damerau_levenshtein 其实就是描述两个字符串之间的差异,damerau_levenshtein 距离越小则两个字符串越接近
该函数的将输入的错误单词跟正确的候选词挨个计算 damerau_levenshtein 距离,
最后排序下 damerau_levenshtein 距离输出最小的候选词
rustup的 damerau_levenshtein 来自 strsim 库,除了 rustup, darling 等知名库也导入了 strsim 库
查阅维基百科的 damerau_levenshtein 词条后发现 damerau_levenshtein 的同义词是 levenshtein_distance 和 edit_distance
用 rustc 源码竟然过了算法题
rustc 源码会尽量不用第三方库,所以我猜测 rustc 不会像 rustup 那样用 strsim 源码,那就看看 rustc 的实现会不会更好
在 Rust 的 github 仓库中搜索edit distance关键字能找到Make the maximum edit distance of typo suggestions 的 commit
typo 就是单词拼写错误的意思,本文也会将单词拼写错误简称为 typo
顺着这个 commit 的改动在 find_best_match_for_name 函数内调用了 lev_distance 函数去计算两个字符串的编辑距离
edit_distance 是个动态规划算法或字符串算法的经典问题,果然 leetcode 上有 edit_distance 的算法题
我拿 rustc 源码的 lev_distance 函数在 leetcode上通过 edit_distance 一题
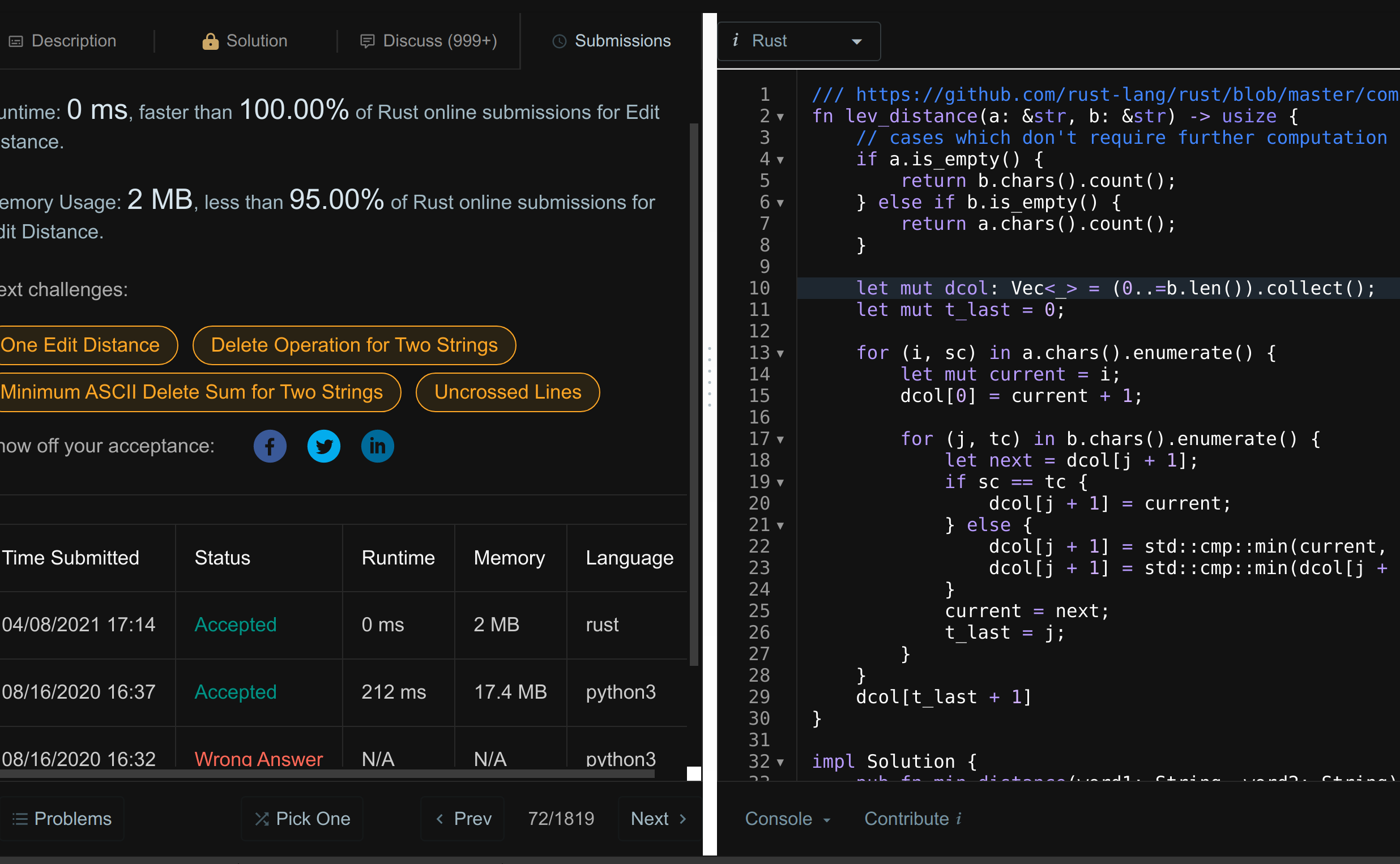
用 strsim 的相关函数也能通过编辑距离这题,但是运行耗时 4ms 会比 rustc 源码运行耗时 0ms 慢点
原因是 strsim 的 edit_distance 算法动态规划的空间复杂度是 O(n^2),而 rustc 的实现空间复杂度是 O(n)
edit_distance 算法
从 rustc 源码的 lev_distance 函数签名 fn lev_distance(a: &str, b: &str) -> usize 来看
输入的是两个字符串 a 和 b, 返回值表示 a 和 b 的 edit_distance
edit_distance 表示从字符串 a 修改成 b 或从字符串 b 修改成 a 至少需要的操作(插入/删除/替换一个字母)次数
例如一个拼写错误的单词 bpple 需要一次替换操作,将第一个字母 b 替换成 a 才能变成 apple
所以字符串 bpple 和 apple 之间的 edit_distance 就是 1
以下是一段 edit_distance 的二维数组 dp 状态的实现,可以结合代码注释进行理解,详细的推断和动态规划状态转移方程可以看 leetcode 的官方题解
#![allow(unused)] fn main() { /// 从字符串word1修改成word2至少需要多少次操作(replace/insert/delete) #[allow(clippy::needless_range_loop)] fn edit_distance_dp(word1: String, word2: String) -> i32 { let (word1, word2) = (word1.into_bytes(), word2.into_bytes()); let (word1_len, word2_len) = (word1.len(), word2.len()); // # dp[i][j]表示word1[..i]至少需要多少次操作(replace/insert/delete)替换成B[..j] // 很容易想到的其中一种状态转移的情况: 如果word1[i]==word2[j],那么dp[i][j]==dp[i-1][j-1] let mut dp = vec![vec![0; word2_len+1]; word1_len+1]; for i in 0..=word1_len { // 需要i次删除操作才能让word1[..i]修改成空的字符串word2[..0] dp[i][0] = i; } for j in 0..=word2_len { // 需要j次插入操作才能让空字符串word1[..0]修改成word2[..j] dp[0][j] = j; } for i in 1..=word1_len { for j in 1..=word2_len { if word1[i-1] == word2[j-1] { dp[i][j] = dp[i-1][j-1]; } else { // dp[i-1][j-1] + 1: word1[i-1]和word2[i-2]不同,所以替换次数+1, // 如果dp的决策层选择replace操作,dp[i][j]总共操作数等于dp[i-1][j-1]+1 // d[i-1][j]表示往word1末尾插入word2[j],dp[i][j-1]表示word1删掉末尾的字母让word1和word2更接近 dp[i][j] = dp[i-1][j-1].min(dp[i-1][j]).min(dp[i][j-1]) + 1; } } } dp[word1_len][word2_len] as i32 } }
由于 rustc 源码为了性能选用了一位数组存储动态规划的状态,用到了很多状态压缩、滚动数组之类的技巧,较难理解,本文就不对 rustc 的动态规划 edit_distance 算法做解释
引用 rustc 编辑距离的函数
rustc 动态链接库?
考虑到 rustc 源码的 lev_distance 会比 strsim 库性能略微好点,所以就直接调 rustc 源码的 lev_distance 就行了
当我尝试在代码中加入 extern crate rustc 时就出现以下报错:
error[E0462]: found staticlib
rustcinstead of rlib or dylib
然后 rustc 会提示找到个类似的静态链接库文件
/home/w/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/x86_64-unknown-linux-gnu/lib/librustc-nightly_rt.asan.a
然后我试着用 nm 命令去读取库文件的函数符号表
$ nm -D librustc-nightly_rt.tsan.a
...
sanitizer_linux_s390.cpp.o:
nm: sanitizer_linux_s390.cpp.o: no symbols
sanitizer_mac.cpp.o:
nm: sanitizer_mac.cpp.o: no symbols
sanitizer_netbsd.cpp.o:
nm: sanitizer_netbsd.cpp.o: no symbols
...
发现里面有一个 sanitizer_netbsd.cpp 的文件,网上搜索得知这是 llvm 的源文件
所以这些 librustc-nightly_rt 开头的库全是 llvm 相关的静态链接库,并不是 rustc 的库
rustc-ap-rustc_span
我相信我编译过很多像 rust-analyzer, racer 等静态分析的库,说不定电脑本地的 cargo 缓存就有 rustc 源码的 lev_distance.rs
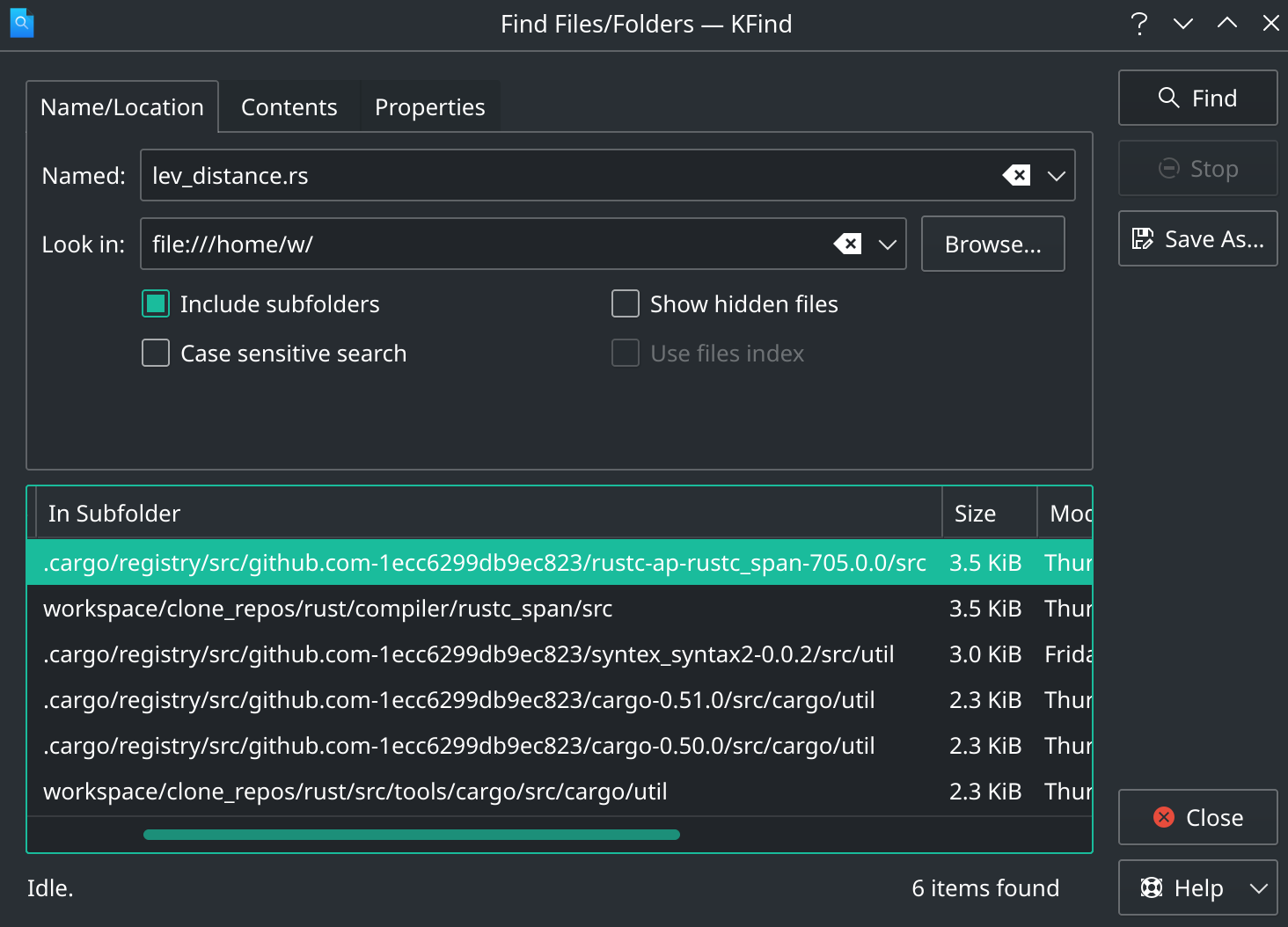
果然发现 rustc-ap-rustc_span 这个 crate 就有 lev_distance 函数
再参考 StackoverFlow 的问题 How to use rustc crate? 和 racer 源码后发现
而以 rustc-ap-rustc_ 命名开头的库都是由 Rust 官方团队的 alexcrichton
定期从 rustc 源码中同步代码并发布到 crates.io 中
为了进一步验证带rustc-ap前缀的库是不是从 rustc 源码导出的,再看看很可能用到部分 rustc 源码的 rust-analyzer
[w@w-manjaro rust-analyzer]$ grep -r --include="*.toml" "rustc-ap" .
./crates/syntax/Cargo.toml:rustc_lexer = { version = "714.0.0", package = "rustc-ap-rustc_lexer" }
果然发现 rust-analyzer 用到了 rustc-ap-rustc_lexer 这个库,毕竟 rust-analyzer 是做静态分析的,跟编译器的部分功能有点重合很正常
其实像 rust-analyzer 和 racer 等静态分析工具都会用到 rustc-ap-rustc_* 这样命名开头的 rustc 编译器组件库
我参考 racer 源码可以在 Cargo.toml 中这么引入 rustc_span,进而使用 rustc_span 的 lev_distance 函数
rustc_span = { package="rustc-ap-rustc_span", version="714.0.0" }
rustc-dev component
阅读 rustup component 相关文档得知,rustc-dev 组件包含了 rustc 的动态链接库和源码(方便静态分析)
rustup component add rustc-dev
然后就可以使用 rustc 编译器的各种组件
#![allow(unused)] #![feature(rustc_private)] fn main() { extern crate rustc_span; }
rust-analyzer 对 rustc 静态分析
然后在 Cargo.toml 中加入以下内容,
[package.metadata.rust-analyzer]
rustc_private = true
然后 rust-analyzer 能对 rustc API 的使用进行静态分析
然后参考 rust-analyzer 的这两个 #6714, #7589
想让 rust-analyzer 对 rustc 函数的使用进行静态分析,需要设置 rustc 源码的路径:
"rust-analyzer.rustcSource": "/home/w/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/rustc-src/rust/compiler/rustc_driver/Cargo.toml"
rustc-dev component 会提供 rustc-src 也就是 rustc 源码
目前 rust-analyzer 还不支持 extern crate test 的静态分析,但我看 rust-src component 提供了 test crate 的源码:
/home/w/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/test/Cargo.toml
所以 rust-analyzer 和 intellij-rust 将来有望支持 test crate 的静态分析
不过像 libc 虽然 rustup 每个 toolchain 都装了 libc 的 rlib 类型的动态链接库,可惜 rust-src component 没有包括 libc 源码
所以用 extern crate libc 的方式引入 toolchain 自带的 libc 还是不能做静态分析的
语料库
拼写错误候选词建议需求的实现思路可以是: 对常用英语单词的每个单词跟拼写错误的单词去计算编辑距离,取编辑距离最近的 5 个单词作为获选词建议
字符串间编辑距离的算法可以直接用 rustc 源码的 lev_distance,常用英语单词表则需要一个语料库
/usr/share/dict/words
mac 和树莓派的 raspbian 系统都在 /usr/share/dict/words 存放英语语料库,用于系统预装的记事本等应用进行拼写错误检查
像 ubuntu_desktop 或 raspbian 这种带图形桌面环境的 linux 发行版一般会在 /usr/share/dict/words 内置语料库
如果没有找到语料库,可以通过 sudo apt install wbritish 或 sudo pacman -S words 进行安装
除了用操作系统自带的语料库,还可以选用 github 的 english-words 仓库作为语料库
拼写错误检查器 trait
为了方便更换语料库存储的数据结构,需要先对语料库的行为抽象出一个 trait,便于重构或复用代码
#![allow(unused)] fn main() { pub trait TypoSuggestion: Sized + Default { const MAX_EDIT_DISTANCE: usize = 1; const NUMBER_OF_SUGGESTIONS: usize = 5; fn insert(&mut self, word: String); fn read_os_dictionary(&mut self) { /** OS_DICTIONARY_PATH macos/raspbian: os built-in diction ubuntu: sudo apt install wbritish archlinux: sudo pacman -S words */ const OS_DICTIONARY_PATH: &str = "/usr/share/dict/words"; use std::io::{BufRead, BufReader}; let word_file = BufReader::new(std::fs::File::open(OS_DICTIONARY_PATH).unwrap()); for word in word_file.lines().flatten() { self.insert(word) } } /// return type Self must bound Sized fn new() -> Self { let mut typo_checker = Self::default(); typo_checker.read_os_dictionary(); typo_checker } fn is_typo(&self, word: &str) -> bool; fn typo_suggestions(&self, word: &str) -> Vec<String>; } }
trait TypoSuggestion 核心就两个函数: fn is_typo() 判断输入的单词是否在语料库中, fn typo_suggestions() 如果输入的单词拼写错误才返回若干个最相似的候选词建议
Vec 实现候选词建议
既然操作系统语料库是个每行都是一个单词的文本文件,很容易想到用 Vec<String> 去存储每个单词,我将这个实现命名为: VecTypoChecker
#![allow(unused)] fn main() { #[derive(Default)] pub struct VecTypoChecker { words: Vec<String>, } impl TypoSuggestion for VecTypoChecker { fn insert(&mut self, word: String) { self.words.push(word); } fn is_typo(&self, word: &str) -> bool { !self.words.contains(&word.to_string()) } fn typo_suggestions(&self, word: &str) -> Vec<String> { let input_word = word.to_string(); if !self.is_typo(&input_word) { return vec![]; } let mut suggestions = vec![]; for word in self.words.iter() { let edit_distance = rustc_span::lev_distance::lev_distance(&input_word, word); if edit_distance <= Self::MAX_EDIT_DISTANCE { suggestions.push(word.clone()); } if suggestions.len() > Self::NUMBER_OF_SUGGESTIONS { break; } } suggestions } } }
VecTypoChecker 的测试代码如下:
#![allow(unused)] fn main() { #[test] fn test_typo_checker() { let typo_checker = VecTypoChecker::new(); let input_word = "doo"; println!( "Unknown word `{}`, did you mean one of {:?}?", input_word, typo_checker.typo_suggestions(input_word) ); } }
测试代码的输出结果示例:
Unknown word
doo, did you mean one of ["boo", "coo", "dao", "do", "doa", "dob"]?
VecTypoChecker 的时间复杂度
is_typo 要遍历整个数组判断输入单词是否在单词表里,显然时间复杂度是 O(n)
假设单词表中平均单词长度为 k,输入单词的长度为 L,typo_suggestions 的时间复杂度则要 O(n*L*k)
valgrind 和 memusage 测量堆内存使用
其实用数组去存储语料库的每个单词的内存利用率是很低的,很多单词都是重复部分很多
先用 wc 和 du 命令查看操作系统单词表的收录的单词数和占用硬盘空间大小
[w@w-manjaro ~]$ wc -l /usr/share/dict/words
123115 /usr/share/dict/words
[w@w-manjaro ~]$ du -h `readlink -f /usr/share/dict/words`
1.2M /usr/share/dict/american-english
那 12 万个单词 1.2M 的单词文件以数组的数据结构在内存中需要占用多少空间呢?
由于 Rust 标准库的 std::mem::size_of 只能测量栈上的空间,标准库没有测量智能指针在堆上占用空间的方法
所以只能借助可执行文件的内存分析工具 valgrind --tool=massif 或 memusage
#![allow(unused)] fn main() { #[test] fn test_vec_typo_checker() { let _ = VecTypoChecker::new(); } }
在 memusage 工具内运行上述单元测试,测试内只进行将操作系统语料库读取成 Vec<String> 的操作
memusage cargo test test_vec_typo_checker
这里只关注 memeusage 输出结果的堆内存峰值信息:
Memory usage summary: heap total: 4450158, heap peak: 4409655, stack peak: 8800
VecTypoChecker::new() 过程的堆内存峰值 大约是 4.2 MB,可能有些 Rust内部对象 堆内存使用会影响结果
所以我效仿称重是要「去皮」的操作,让 memusage 测量一个 Rust 空函数的运行时堆内存峰值,空函数的堆内存峰值是 2-3 kb
Rust 其它的一些堆内存使用相比 VecTypoChecker::new() 的 4.2 MB 小到可以忽略不计
Trie 前缀树/字典树
1.2M 大约 12 万个单词用数组去存储大约需要 4.2M 的堆空间,显然不是很高效
例如 doc, dot, dog 三个单词,如果用 Vec 数组去存储,大约需要 9 个字节
但是如果用"链表"去存储,这三个单词链表的前两个节点 'd' 和 'o' 可以共用,这样只需要 5 个链表节点大约 5 个字节的内存空间
这样像链表一样共用单词的共同前缀的数据结构叫 trie,广泛用于输入法,搜索引擎候选词,代码自动补全等领域
前缀树的数据结构
正好 leetcode 上也有 Implement Trie (Prefix Tree) 这种实现 trie 的算法题
#![allow(unused)] fn main() { #[derive(Default)] pub struct TrieTypoChecker { children: [Option<Box<Self>>; 26], is_word: bool } }
解读下前缀树数据结构的 children: [Option<Box<Self>>; 26] 字段
26 表示当前节点往下延伸一共能扩展出 26 个小写字母,用 Option 表达了某个小写字母的子节点是否存在
用 Box 是因为参考了 Rust 单链表的实现,我们希望树的节点能分配到堆内存上,否则编译器会报错 recursive type has infinite size
想更深入探讨 Rust 链表相关问题的读者可以自行阅读 too-many-lists 系列文章
前缀树的 is_word 字段表示从根节点到当前节点的路径能组成一个单词
如果没有这个 is_word 标注,那么插入一个 apple 单词时,无法得知 apple 路径上的 app 是不是也是一个单词
#[derive(Default)]的目的是方便创建一个子节点全为 None 的前缀树节点
前缀树的路径压缩
实际生产环境中前缀树实现会比上述实现要复杂得多,要考虑类似「并查集」的「路径压缩」
例如有个单词是aaaaa,那么插入到前缀树就会形成深度为 5 层的树
树的深度过深不够"饱满",这样内存利用率不高,需要把树 压扁 (路径压缩)
前缀树的插入
#![allow(unused)] fn main() { impl TypoSuggestion for TrieTypoChecker { fn insert(&mut self, word: String) { let mut curr_node = self; for letter in word.into_bytes().into_iter().map(|ch| (ch - b'a') as usize) { curr_node = curr_node.children[letter].get_or_insert_with(|| Box::new(Self::default())) } curr_node.is_word = true; } } }
但上述前缀树的插入方法,在读取操作系统的自带的单词表时会 panicked at 'attempt to subtract with overflow'
原因是操作系统的单词表中除了小写字母还有大写字母和单引号
为了简便我们把单词表中的大写字母转为小写再去掉除小写字母以外的字符,这样就能把单词表转为前缀树
#![allow(unused)] fn main() { fn insert(&mut self, word: String) { let word = word .into_bytes() .into_iter() .map(|ch| ch.to_ascii_lowercase()) .filter(|ch| matches!(ch, b'a'..=b'z')) .collect::<Vec<u8>>(); let mut curr_node = self; for letter in word.into_iter().map(|ch| (ch - b'a') as usize) { curr_node = curr_node.children[letter].get_or_insert_with(|| Box::new(Self::default())) } curr_node.is_word = true; } }
再写个构造前缀树并读取操作系统单词表的测试用例,跟数组的实现对比下空间复杂度
#![allow(unused)] fn main() { #[test] fn test_trie_typo_checker() { let _ = TrieTypoChecker::new(); } }
memusage cargo test test_trie_typo_checker
memusage 测试结果显示,前缀树存储 12 万 个单词只需要花 784 kb 的堆内存空间
相比单词表磁盘文件占用 1.2M 硬盘空间,用前缀树存储只 700 多 kb 确实有「压缩」的效果
相比用数组存储单词表消耗 4.2M 内存,前缀树在空间复杂度上大约有 80% 的提升
再写一个性能测试对比数组和前缀树读取单词表的时间复杂度
#![allow(unused)] #![feature(test)] fn main() { extern crate test; use typo_checker::{TypoSuggestion, VecTypoChecker, TrieTypoChecker}; #[bench] fn bench_vec_read_dictionary(bencher: &mut test::Bencher) { bencher.iter(|| { VecTypoChecker::new(); }); } #[bench] fn bench_trie_read_dictionary(bencher: &mut test::Bencher) { bencher.iter(|| { TrieTypoChecker::new(); }); } }
benchmark 的运行结果:
Running unittests (target/release/deps/bench-c073956b9e337dbe)
running 2 tests
test bench_trie_read_dictionary ... bench: 39,724,024 ns/iter (+/- 2,954,476)
test bench_vec_read_dictionary ... bench: 11,928,761 ns/iter (+/- 386,083)
发现前缀树插入 12 万个单词比数组快 3 倍,而且前缀树插入单词时还有「去重」的功能,数组插入单词想去重还要额外的性能开销
小结: 前缀树读单词表,时间复杂度上比数组快 3 倍多,空间复杂度上比数组节约 80%
前缀树的查询
查询某个单词是否在前缀树内,其实就是前文提到的 TypoSuggestion trait 的 is_typo 函数
#![allow(unused)] fn main() { fn is_typo(&self, word: &str) -> bool { let word = word.as_bytes(); let mut curr_node = self; for letter in word { let index = (letter - b'a') as usize; match curr_node.children[index] { Some(ref child_node) => { curr_node = child_node.as_ref(); } None => { return true; } } } !curr_node.is_word } }
再写一个 benchmark 对比数组和前缀树的查询功能
#![allow(unused)] fn main() { #[bench] fn bench_vec_search(bencher: &mut test::Bencher) { let typo_checker = VecTypoChecker::new(); bencher.iter(|| { assert_eq!(typo_checker.is_typo("doo"), true); assert_eq!(typo_checker.is_typo("lettuce"), false); }); } #[bench] fn bench_trie_search(bencher: &mut test::Bencher) { let typo_checker = TrieTypoChecker::new(); bencher.iter(|| { assert_eq!(typo_checker.is_typo("doo"), true); assert_eq!(typo_checker.is_typo("lettuce"), false); }); } }
查询功能的测试结果:
test bench_trie_search ... bench: 8 ns/iter (+/- 2)
test bench_vec_search ... bench: 351,254 ns/iter (+/- 176,276)
小结: 查询某个单词是否在前缀树比数组快了 5 个数量级
前缀树的编辑距离
虽说前缀树的插入和查询都比数组快,但前缀树的删除比数组要难,前缀树编辑距离的实现更是非常难(需要记忆化深度优先搜索等诸多复杂算法)
知乎上有个相关的提问: 鹅厂面试题,英语单词拼写检查算法 - 知乎
很多回答都引用了这篇文章
说实话最佳回答或上述文章都大量使用了 Python 的字符串拼接,每次拼接操作都会 new 一块字符串的堆内存
这样频繁字符串拼接操作性能开销大,不能让我满意
#![allow(unused)] fn main() { impl TypoSuggestion for TrieTypoChecker { fn typo_suggestions(&self, word: &str) -> Vec<String> { let mut dfs_helper = DfsHelper { suggestions: vec![], path: vec![], typo_checker: &self, }; dfs_helper.dfs(&self); dfs_helper.suggestions } } /// 为了偷懒,把dfs一些不关键的递归间全局共享的状态放到一个结构体 struct DfsHelper<'a> { /// 返回值 suggestions: Vec<String>, /// 当前深度优先搜索,从根节点到当前节点的遍历路径 path: Vec<u8>, typo_checker: &'a TrieTypoChecker, } impl<'a> DfsHelper<'a> { fn dfs(&mut self, curr_node: &TrieTypoChecker) { } } }
由于搜索的是前缀树内相似的单词,所以不适合用广度优先搜索去遍历,用递归实现深度优先搜索比较方便
为了减少 dfs 函数传参个数以及便于增删和管理递归函数的「无需回溯」的入参,我定义了一个 DfsHelper
首先由于前缀树整体是个树,不方便像数组实现遍历所有单词挨个与输入单词之间计算编辑距离
虽然较难前缀树的编辑距离实现难度很高,但是还是先写出单元测试,以 TDD 的方式开发逐渐迭代和逼近正确的实现代码
#![allow(unused)] fn main() { #[test] fn test_trie_typo_checker() { const TEST_CASES: [(&str, &[&str]); 1] = [ ("doo", &["boo", "coo", "dao", "do", "doa", "dob"]) ]; let typo_checker = TrieTypoChecker::new(); for (input, output) in std::array::IntoIter::new(TEST_CASES) { assert_eq!(typo_checker.typo_suggestions(input), output); } } }
递归的结束条件
由于前文中的 trait TypoSuggestion 的 NUMBER_OF_SUGGESTIONS 参数默认为 5
所以很容易想到一个递归结束条件就是 当前深度优先搜索已经找到 5 个 候选词了
另一个递归结束条件就是输入单词已经被扫描完了
深度优先搜索的剪枝
如果当前遍历到的单词跟输入的单词的编辑距离超过 1,就可以进行「剪枝」
这样能大大减少遍历前缀树的节点数量,作者水平有限,可能还有其它递归结束条件和剪枝条件没能想到
简陋的编辑距离搜索
#![allow(unused)] fn main() { impl TypoSuggestion for TrieTypoChecker { // ... fn typo_suggestions(&self, word: &str) -> Vec<String> { let mut dfs_helper = DfsHelper { input_word: word.as_bytes().to_vec(), input_word_len: word.len(), output_suggestions: vec![], path: vec![], }; dfs_helper.dfs(&self, 0, 1); dfs_helper.output_suggestions } } struct DfsHelper { /// 输入的单词 input_word: Vec<u8>, input_word_len: usize, /// 返回值 output_suggestions: Vec<String>, /// 当前深度优先搜索,从根节点到当前节点的路径(path root to curr_node) path: Vec<u8>, } impl DfsHelper { fn dfs(&mut self, curr_node: &TrieTypoChecker, input_word_index: usize, edit_times: i32) { if edit_times < 0 { return; } if input_word_index == self.input_word_len { if curr_node.is_word { self.output_suggestions.push(unsafe { String::from_utf8_unchecked(self.path.clone()) }); } if edit_times == 0 { return; } // 输入单词遍历遍历完了,如果还有编辑次数可用,则用剩余的编辑次数给当前dfs遍历路径组成的单词词尾巴追加字母 // 例如 input_word="do", trie从根到当前节点的路径d->o遍历完还剩余1次编辑次数,则可以用做增加操作,把g加到当前路径中 for (i, child_node_opt) in curr_node.children.iter().take(26).enumerate() { if let Some(child_node) = child_node_opt { self.path.push(b'a' + i as u8); self.dfs(child_node, input_word_index, edit_times-1); self.path.pop().unwrap(); } } return; } if self.output_suggestions.len() >= TrieTypoChecker::NUMBER_OF_SUGGESTIONS { return; } let curr_letter_index = (self.input_word[input_word_index] - b'a') as usize; for (i, child_node_opt) in curr_node.children.iter().take(26).enumerate() { if let Some(child_node) = child_node_opt { if i == curr_letter_index { self.path.push(self.input_word[input_word_index]); self.dfs(child_node, input_word_index+1, edit_times); self.path.pop().unwrap(); } else { // replace self.path.push(b'a' + i as u8); self.dfs(child_node, input_word_index+1, edit_times-1); self.path.pop().unwrap(); } } } } } }
输出看上去很接近拼写错误单词:
Unknown word
doo, did you mean one of ["boo", "coo", "doa", "dob", "doc", "dod", "doe", "dog", "don", "doom", "door", "dos", "dot", "dow", "doz"]?
遗憾的是还未能实现编辑距离的删除操作,相比知乎上那个最佳回答还少了很多情况的判断
再看看单元测试的情况:
thread 'test_trie_typo_checker' panicked at 'assertion failed: `(left == right)`
left: `["boo", "coo", "doa", "dob", "doc", "dod", "doe", "dog", "don", "doom", "door", "dos", "dot", "dow", "doz"]`,
right: `["boo", "coo", "dao", "do", "doa", "dob"]`', src/lib.rs:182:9
首先肉眼看错误单词 doo 返回的候选词基本满足,期望返回 5 个候选词,结果超过返回超过 5 个
但是没有将 do 收录进候选词,因为上述代码还没支持编辑距离的删除操作
其次候选词的排序似乎跟数组的实现不一样,原因是这个前缀树的遍历并不是跟数组按字母顺序遍历单词表一样
准确的说法是26 叉树的深度优先回溯搜索,类似的算法可以参考 leetcode lexicographical 一题
所以单元测试的期待值校验应该改成,遍历每一个候选词用 rustc_span::lev_distance::lev_distance 去计算跟输入单词之间的编辑距离
如果全部候选词的编辑距离小于等于 1 则测试通过
简陋编辑距离实现的不足
- 还没支持字符串编辑距离的删除操作
- 没有测试入参 edit_times >= 2 的情况
- 应该用迭代模拟递归,递归代码对编译器不友好,难优化
- 应当做成 iterator 或 generator 可以逐个输出值,返回值要实现标准库相关的 Iter trait
- 改良测试用例的期待值校验方法
单词拼写检查器还能干什么
作者一开始参与 sqlx 项目也是只能提 PR 修些 typo (typo 就是单词拼写错误的意思)
通过修 typo 的过程更仔细的阅读了多遍源码,更深入理解 sqlx 的架构,日后渐渐修复了 sqlx sqlite 部分的几个 Bug
本文讲述的这个拼写检查器,还可以用来检查开源项目的一些 typo
Rust 2021 年 4 月的这个 PR 只是修复些拼写错误,但也算对 Rust 的开源社区做出贡献
希望更多人能像作者这样从修复 typo 开始参与开源项目,慢慢能解决更困难的 issue,逐渐为开源社区做出更大的贡献
项目的 github 链接与总结
拼写错误候选词建议源码的 github 仓库链接: https://github.com/pymongo/typo_checker (持续更新,欢迎 star)
总的来说前缀树存储单词表性能会比数组优秀太多,后续打算添加一个检查一篇文章的单词拼写错误例子
然后再加一个实时检测 android 的 EditText 文本输入组件的单词拼写错误的示例