Tokio Internal 之 任务调度
作者:韩冰(Tony) / 后期编辑:张汉东
这是一个系列文章:Tokio Internal: https://tony612.github.io/tokio-internals/
本篇精选其中相对独立的一篇《Task scheduler》,对该系列感兴趣可以去看完整系列文章。
选择合适的 task 来运行是调度器非常重要的一个逻辑,如果处理不好,可能会使调度很慢,也可能会使不同的 task 没有被公平地执行,甚至有些 tasks 可能一直得不到执行。我们来看一下 tokio 中是怎么解决这些问题的。
各种 run queue
我们来看 Tokio 中取下一个 task(next_task)以及 steal_task 的代码:
#![allow(unused)] fn main() { // core.next_task: fn next_task(&mut self, worker: &Worker) -> Option<Notified> { if self.tick % GLOBAL_POLL_INTERVAL == 0 { worker.inject().pop().or_else(|| self.next_local_task()) } else { self.next_local_task().or_else(|| worker.inject().pop()) } } -------------------------- // self.next_local_task: fn next_local_task(&mut self) -> Option<Notified> { self.lifo_slot.take().or_else(|| self.run_queue.pop()) } -------------------------- // core.steal_work: let num = worker.shared.remotes.len(); let start = self.rand.fastrand_n(num as u32) as usize; for i in 0..num { let i = (start + i) % num; // Don't steal from ourself! We know we don't have work. if i == worker.index { continue; } let target = &worker.shared.remotes[i]; if let Some(task) = target.steal.steal_into(&mut self.run_queue) { return Some(task); }
可以看到,Worker 会从多个地方取 task,按顺序依次是:
-
LIFO slot
-
自己的 local queue
-
global queue
-
从其他 worker 的 queue(remotes) 中 steal 任务
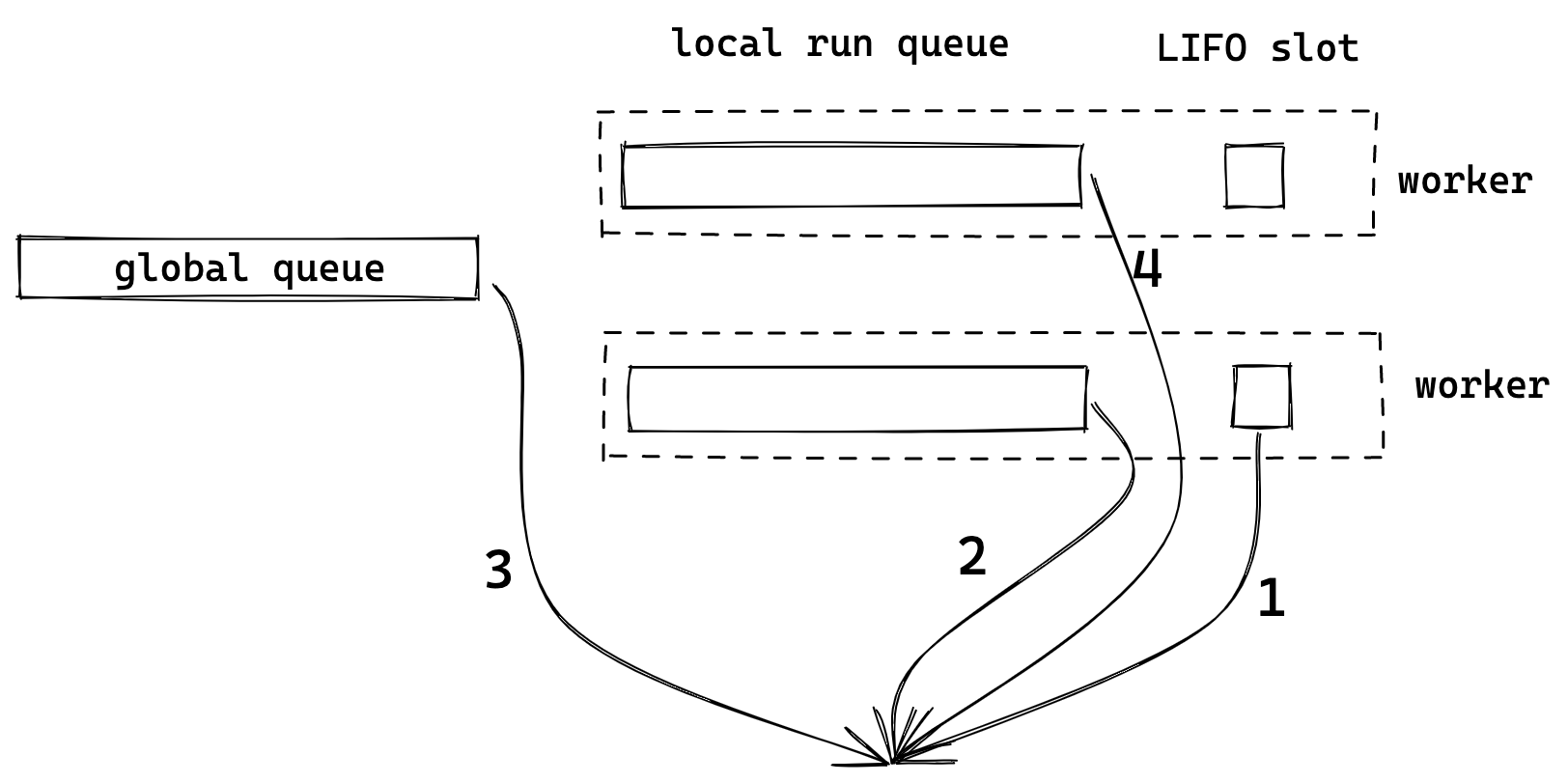
Global queue 肯定需要,但如果只有一个 global queue,每个 worker 从其中取 task 时,都需要加锁,会影响性能。因此给每个 worker 增加自己的 local queue 是很自然的选择,worker 可以优先从自己的 local queue 中取任务。
global 和 local 这两种 queue 都是 FIFO 的,这对于公平性很好,先到先得嘛,但不好的地方是 locality 带来的性能,每个 task 切换执行时,之前 CPU 的缓存就没用了。LIFO slot 就是为了改善这种问题的,它 (似乎)是从 Go 里借鉴来的一个机制,可以解决一些场景 locality 问题。除非是 task 主动 yield,否则当 task 被调度时,会优先考虑放到 LIFO slot(相当于是 queue 的最前边),这个 task 会被优先执行。
比如在一个 task 中 spawn 了另外一个 task,并且有一些变量需要被 move 到新的 task 中,这时如果新的这个 task 能够先被运行的话,这些变量在 CPU 中的缓存就能得到有效利用。Tokio 代码中还提到了 LIFO 可以减少 message passing 中的延迟。比如,当一个 task 向另一个 task 通过 channel 发消息,如果 task 收到消息后可以先被执行,就可以减少因为在 run queue 中排队带来的延迟。
LIFO 可以带来更好的性能,但也会牺牲公平性,因此 LIFO slot 目前只有一个,当这个 LIFO slot 已被占用时,原来的任务就会被转移到 run queue 末尾,而新的 task 则会被放在 LIFO slot 中。LIFO slot 对于性能和公平性,可以实现一定程度上的平衡。
任务的窃取也是调度器中常见的机制,当 global 和 local queue 中都没有 task 可以执行,就会尝试去 "steal" 其他 worker 的任务,这样可以平衡不同 worker 的任务量。Tokio 会随机挑一个 worker 开始尝试窃取,并且会窃取一半的任务,如果那个 worker 也没有任务,就会尝试窃取下一个 worker。不过 LIFO slot 的任务并不会被窃取。
Starvation 问题
虽然不同类型的 queue 和 work stealing 机制可以带来不错的性能和公平性,但还不够,tasks 依然可能会被“饿死”(starvation)。下边描述了几种常见的场景,和 Tokio 中的解决方法。
一个 task 执行过久
如果一个 task 执行很久,最坏情况是进入了死循环,那当前 worker 的 queue 中的 tasks 就要等待更长时间才能得到执行,甚至是一直不会被执行。我们知道,目前 Rust runtime 中无法抢占式调度(preempt)这样的 task,主要还是需要开发者自己进行代码“协同”。
但 Tokio 也有机制来改善这类问题,比如在 2.5 见过的 coop module,在 task 运行之前会调用
#![allow(unused)] fn main() { coop::budget(|| { }) }
它会创建一个 thread local 的 counter,目前初始值是 128。调用 coop::poll_proceed 会把 counter 减 1,当减小到 0 时,就会返回 Pending。而 Tokio 中在 poll 之前都会先调用 coop::poll_proceed 来判断是否超过 budget,如果超过,就会直接返回而不会调用实际的 poll。比如 2.5 中提过的 poll_ready 以及 tokio mpsc recv 等方法里都调用了它。
不过即便是有 coop ,如果是纯 CPU 的计算,Tokio 没办法了。当然这种还是用 tokio::task::spawn_blocking 比较好。
Global queue 中的任务被饿死
因为 local queue 中任务的优先级比 global queue 要高,如果一个 task 一直没有执行结束,比如一个 TCP server 的连接不停有新的数据从 client 发过来,于是它不停被挂起、放在队列、运行,这样 global queue 的任务就一直得不到运行。
Tokio 会用 worker 的 tick(和 3.1 的 driver tick 不同)来记录 worker 在循环中运行的次数,在运行 task 或者 park 之前就会把 tick 加 1。而当取 task 时,就会判断是否运行了一定次数,是的话,就会从先从 global queue 中取 task 来运行,其实就是本章第一段代码。GLOBAL_POLL_INTERVAL 目前取值是 61,是从 Go 中 copy 来的。
#![allow(unused)] fn main() { fn next_task(&mut self, worker: &Worker) -> Option<Notified> { if self.tick % GLOBAL_POLL_INTERVAL == 0 { worker.inject().pop().or_else(|| self.next_local_task()) } else { self.next_local_task().or_else(|| worker.inject().pop()) } } }
LIFO slot 导致的饿死
LIFO slot 因为改变了 task 的优先级,就可能会导致其他任务被饿死。有一种可能是,一个 worker 中的两个 task 一直在互相发消息,这两个 task 就会一直在 LIFO slot 中,导致 local queue 的任务得不到执行,有个测试用例 专门来测试这种场景。Tokio 的解决方法是,对 LIFO slot 做了特殊处理:
#![allow(unused)] fn main() { coop::budget(|| { task.run(); // As long as there is budget remaining and a task exists in the // `lifo_slot`, then keep running. loop { // Check for a task in the LIFO slot let task = match core.lifo_slot.take() { Some(task) => task, None => return Ok(core), }; if coop::has_budget_remaining() { // Run the LIFO task, then loop *self.core.borrow_mut() = Some(core); task.run(); } else { // Not enough budget left to run the LIFO task, push it to // the back of the queue and return. core.run_queue.push_back(task, self.worker.inject()); return Ok(core); } } }) }
一个任务执行后,不会回到之前的 next_task的地方,而是直接看 LIFO slot 中是否有任务可以执行,有就执行 LIFO slot 任务,没有就返回。但这个逻辑是放在一个 coop::budget 调用里的,当没有剩余 budget 时,就把 LIFO 的任务放到 run queue 末尾,从而避免了一直循环执行这两个 LIFO slot 的任务。
Event poll 被饿死
之前说过 Tokio 的 worker 会优先执行 run queue 中的 tasks,当没有任务可执行时,会在 park中 poll events。问题很明显,如果 run queue 一直没有执行完,就不会 poll events。Tokio 用了和 Global queue 饿死问题一样的方案,在取 task 之前,会在 maintenance 里先判断 worker 的 tick 是否运行了 GLOBAL_POLL_INTERVAL 次,是的话就强制 park。
fn maintenance(&self, mut core: Box<Core>) -> Box<Core> { if core.tick % GLOBAL_POLL_INTERVAL == 0 { // Call `park` with a 0 timeout. This enables the I/O driver, timer, ... // to run without actually putting the thread to sleep. core = self.park_timeout(core, Some(Duration::from_millis(0))); // Run regularly scheduled maintenance core.maintenance(&self.worker); } core }
注意这里调用了 park_timeout,并且超时时间为 0,如果当前没有事件的话,就会直接返回,继续执行 tasks,不会等在这里。
总结
Tokio 用了几种不同的 queue,分别解决了不同的问题,并且针对可能出现的 starvation 做了预防。可以看到,虽然并非完美,但 Tokio 在尽力平衡性能、公平性,并且还在不断被优化。