Zellij 的性能优化
- 作者: Aram Drevekenin
- 译者: yct21
过去的几个月里,我们一直工作在 Zellij 的故障修复和性能调优上。在这个过程中,我们发现了不少问题和瓶颈,并采取了一些创造性的手段解决或者绕过它们。
本文我会用图文描述我们遇到的 2 个问题。在处理完这 2 个问题后,我们的应用已经能在性能上和同类产品打成平手,甚至超越它们。
这是 Zellij 的社区维护人员和贡献者共同创造的成果,详情请见后文的致谢部分。
关于本文的代码示例
本文中的代码示例围绕想表达的论点做了酌情简化。由于 Zellij 是一个已用于实际使用的应用,其内部代码可能会涉及和包含无关的细节。如果读者想深入研究的话,在每个代码示例后,有实际代码的链接,包括相关 PR 的链接。
应用的功能与遇到的问题
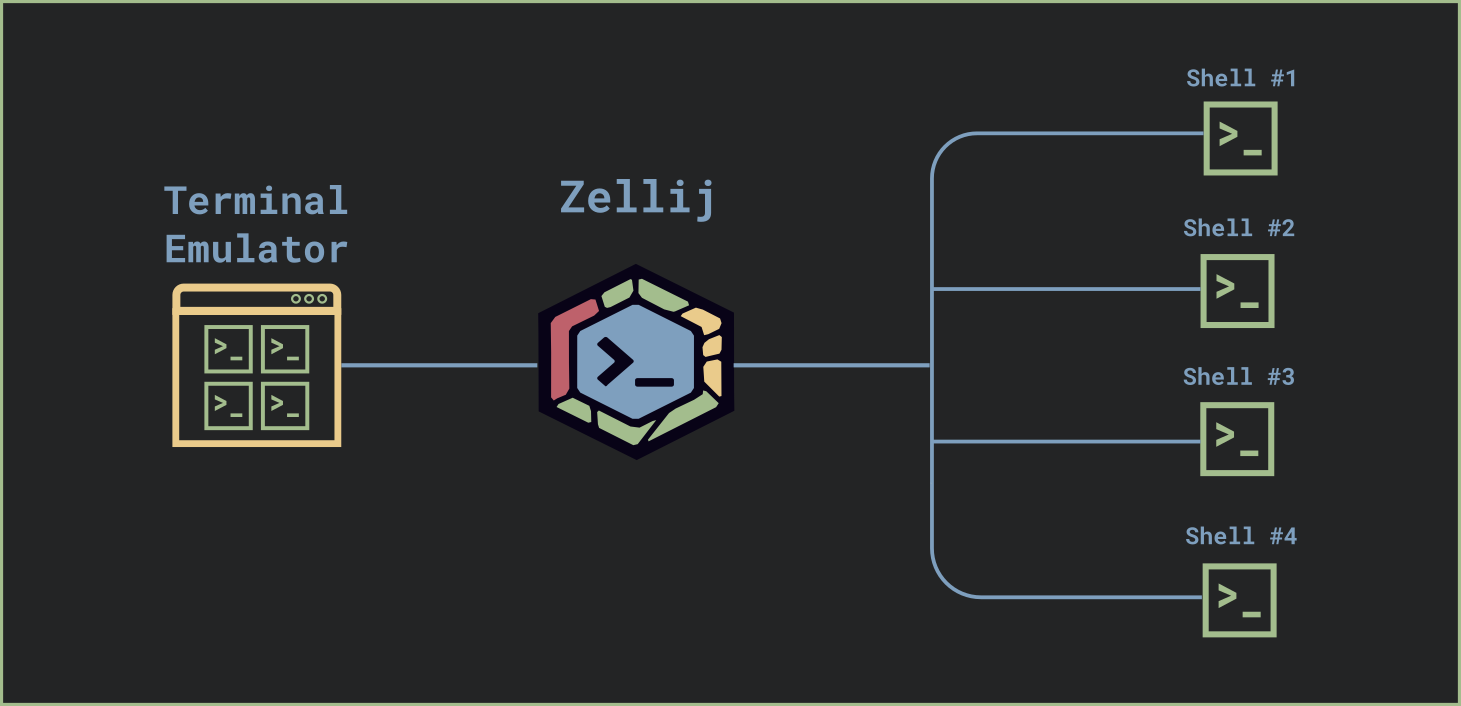
Zellij 是一个终端复用软件,简单来说,这是一个运行于虚拟终端(如 Alacritty, iterm2, Konsole 等)和 shell 之间的应用。
Zellij 中可以创造标签页和窗格,另外由于一直在后台运行,也可以脱离和重连某个会话。Zellij 保存了每个窗格的状态,让用户在重连或者切换标签页的之后还能回到原有的会话中。这个状态包含了窗格中的文本和样式,以及光标的位置等信息。
当某个窗格包含有大量的数据时,应用会遇到严重的性能问题。例如,cat 一个非常大的文件,Zellij 不仅比一个裸的虚拟终端要慢,比其他终端复用软件也要慢上许多。
这里我们深入挖掘这个问题,看看问题的根源是什么,并探索相应的解决方案。
问题流程
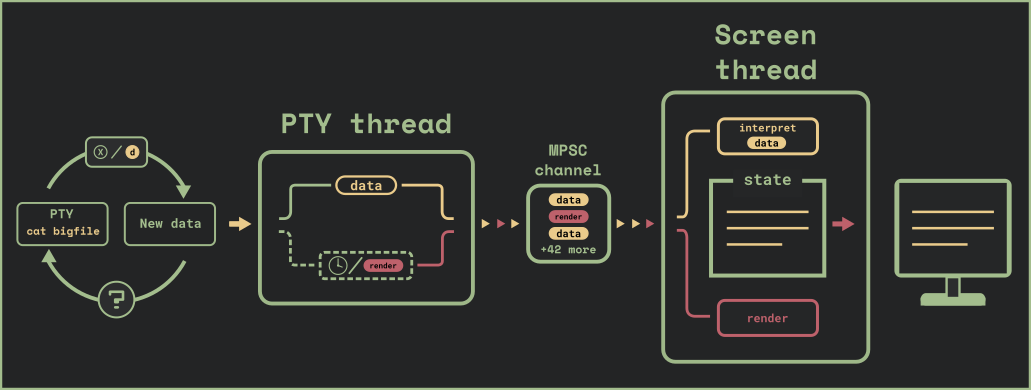
我们采用了多线程的架构,每个线程完成某些特定的任务,并通过 MPSC 通道相互通信。数据的解析与渲染分别由 pty 线程和 screen 线程完成。
pty 线程 会查询 pty,这是我们与 shell(或者其他在终端中运行的程序)的接口。该线程会向 screen 线程发送原始数据,并由其解析数据,构造出这个窗格的内部状态。
另外,每隔一小段时间,pty 线程会给 screen 线程发送 render 消息,让其根据窗格的状态渲染用户的 UI。
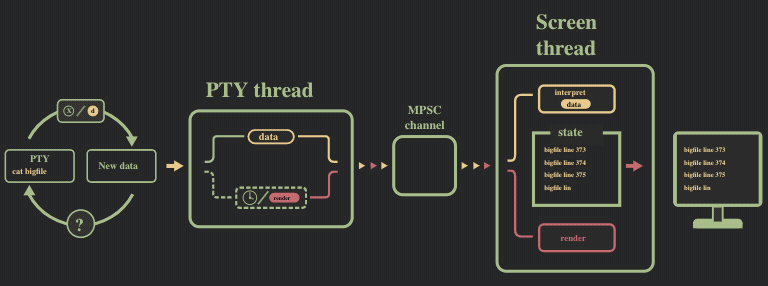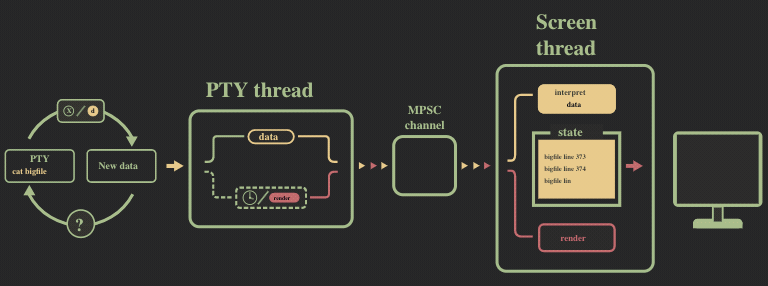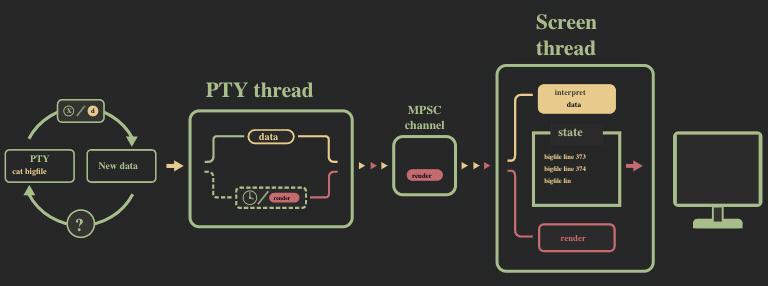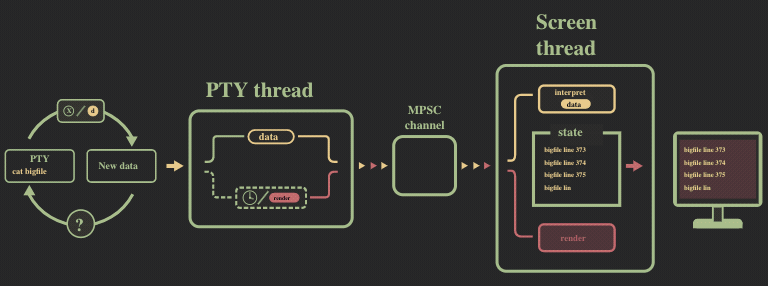
pty 线程会启动一个异步任务,采用一个非阻塞的循环去轮询 pty,检查是否有新的数据。如果没有数据,pty 线程会休眠一段固定的时间。pty 线程在拿到数据后会向 screen 线程发送 data 指令,让其解析数据。此外,在以下情况下,pty 线程会去发 render 指令:
- pty 缓存中没有数据
- 从上次 render 指令发送已经过了 30ms 以上
其中第二种情况是为了用户体验,这样当有大量数据从 pty 传来时,用户可以实时地在屏幕中看到更新。
让我们看一下代码:
#![allow(unused)] fn main() { task::spawn({ async move { // TerminalBytes is an asynchronous stream that polls the pty // and terminates when the pty is closed let mut terminal_bytes = TerminalBytes::new(pid); let mut last_render = Instant::now(); let mut pending_render = false; let max_render_pause = Duration::from_millis(30); while let Some(bytes) = terminal_bytes.next().await { let receiving_data = !bytes.is_empty(); if receiving_data { send_data_to_screen(bytes); pending_render = true; } if pending_render && last_render.elapsed() > max_render_pause { send_render_to_screen(); last_render = Instant::now(); pending_render = false; } if !receiving_data { // wait a fixed amount of time before polling for more data task::sleep(max_render_pause).await; } } } }) }
实际的代码可以参考该链接。
代码排障
为了测试这段流程的性能,我们会 cat 一个 2,000,000 行的文件,并使用 hyperfine,并打开 --show-output 选项,使其不会忽略 stdout 的时间。我们采用 tmux 作为对照组。
hyperfine --show-output "cat /tmp/bigfile" 在 tmux 的运行结果如下(窗格大小: 59 行,104 列):
Time (mean ± σ): 5.593 s ± 0.055 s [User: 1.3 ms, System: 2260.6 ms] Range (min … max): 5.526 s … 5.678 s 10 runs
同样的指令在 Zellij 的运行结果如下(窗格大小:59 行,104 列):
Time (mean ± σ): 19.175 s ± 0.347 s [User: 4.5 ms, System: 2754.7 ms] Range (min … max): 18.647 s … 19.803 s 10 runs
结果并不理想,对此我们要采取一些措施。
难点 1: MPSC 消息通道溢出
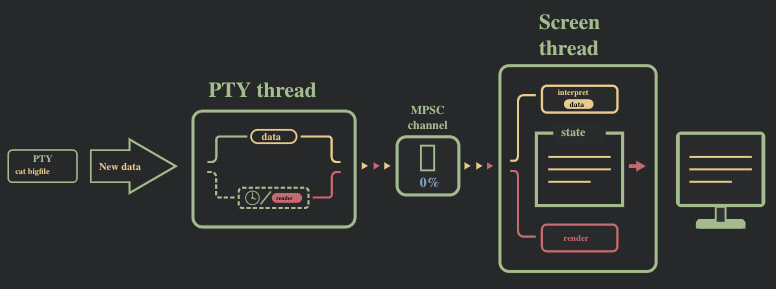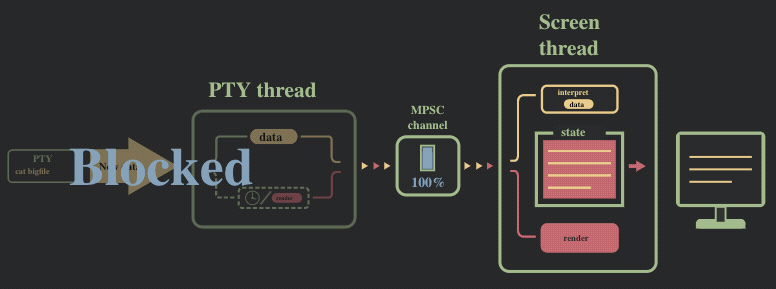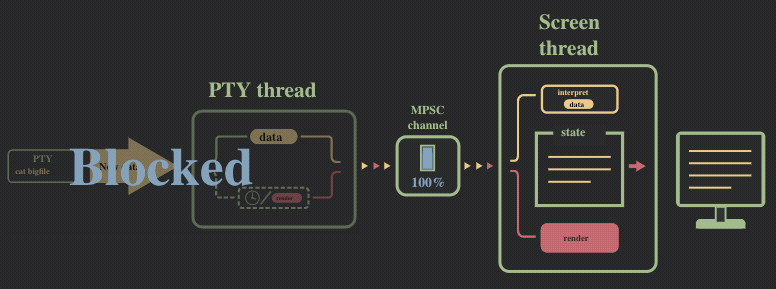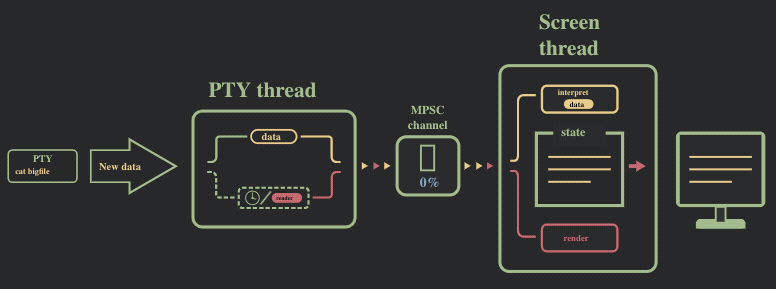
我们遇到的第一个性能瓶颈是 MPSC 消息通道的溢出。为了形象描述这个问题,我们给前面的流程图加个速:
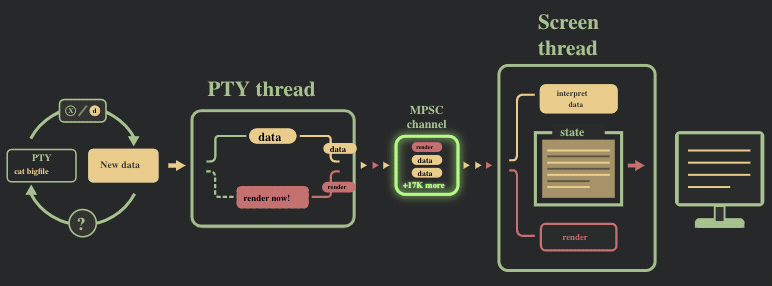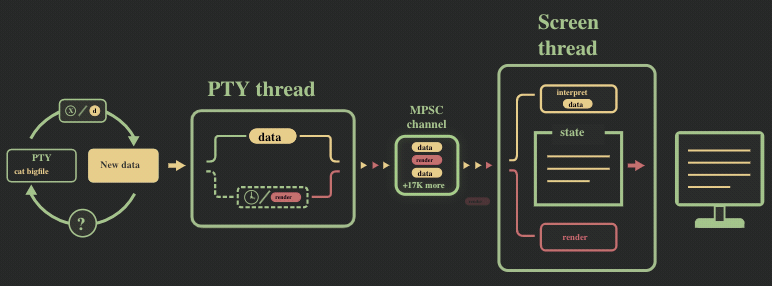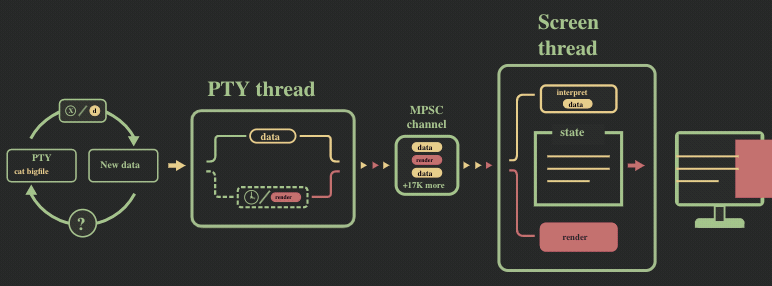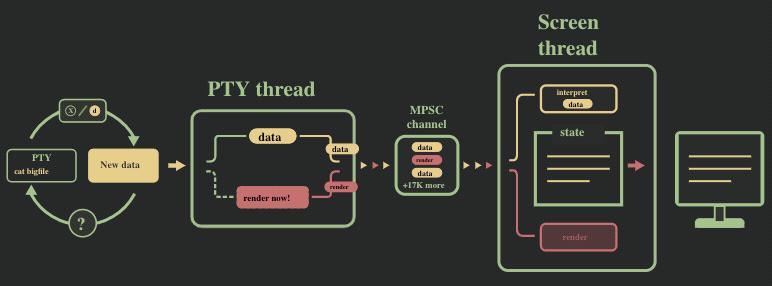
pty 线程和 screen 线程的数据处理速率并不同步,前者向消息通道中发送数据的速度远快于后者消耗的速度。这在以下方面影响了性能:
- 消息通道持续地扩张,不停地占用更多的内存
- 由于 screen 线程随着数据的增加,占用了越来越多的 CPU 时间,原有的 30ms 间隔也变的相对不重要,线程在渲染上会花费比未溢出情况下更多的时间。
解决方案:限制的消息通道的大小(背压机制)
问题的直接解决方法,是对消息通道的缓存大小进行限制,以此给 2 个线程带来了同步。我们将消息通道的大小限制到了很小的一个值(50 条消息),并切换到了 crossbeam,采用了其提供的 select! 宏。
除此之外,我们移除了自己实现的异步流,而是采用 async_std 的 File, 这样就无需在后台进行轮训。
我们来看下相关的代码:
#![allow(unused)] fn main() { task::spawn({ async move { let render_pause = Duration::from_millis(30); let mut render_deadline = None; let mut buf = [0u8; 65536]; // AsyncFileReader is implemented using async_std's File let mut async_reader = AsyncFileReader::new(pid); // "async_send_render_to_screen" and "async_send_data_to_screen" // send to a crossbeam bounded channel // resolving once the send is successful, meaning there is room // for the message in the channel's buffer loop { // deadline_read attempts to read from async_reader or times out // after the render_deadline has passed match deadline_read(&mut async_reader, render_deadline, &mut buf).await { ReadResult::Ok(0) | ReadResult::Err(_) => break, // EOF or error ReadResult::Timeout => { async_send_render_to_screen(bytes).await; render_deadline = None; } ReadResult::Ok(n_bytes) => { let bytes = &buf[..n_bytes]; async_send_data_to_screen(bytes).await; render_deadline.get_or_insert(Instant::now() + render_pause); } } } } }) }
完整的代码可以参考这个链接。
现在的运行流程可以参照下图:
性能提升的度量
让我们回到之前的性能测试,以下是使用 hyperfine --show-output "cat /tmp/bigfile" 的结果(窗格大小:59 行,104 列):
# Zellij before this fix
Time (mean ± σ): 19.175 s ± 0.347 s [User: 4.5 ms, System: 2754.7 ms]
Range (min … max): 18.647 s … 19.803 s 10 runs
# Zellij after this fix
Time (mean ± σ): 9.658 s ± 0.095 s [User: 2.2 ms, System: 2426.2 ms]
Range (min … max): 9.433 s … 9.761 s 10 runs
# Tmux
Time (mean ± σ): 5.593 s ± 0.055 s [User: 1.3 ms, System: 2260.6 ms]
Range (min … max): 5.526 s … 5.678 s 10 runs
可以看到已经有了很大的改进,不过和 tmux 比起来,还不够好。
难题 2: 提升渲染和数据处理的性能
现在我们将有背压的流水线和 screen 线程连接在了一起,如果我们能提升 sceen 线程的工作,也就是数据的处理与渲染,那么应用的性能将得到进一步的提升。
数据解析
数据解析部分会将 ANSI/VT 指令(例如 \033[10;2H\033[36mHi there!),并将其转换成 Zellij 所定义的数据结构。
相关的代码如下:
#![allow(unused)] fn main() { struct Grid { viewport: Vec<Row>, cursor: Cursor, width: usize, height: usize, } struct Row { columns: Vec<TerminalCharacter>, } struct Cursor { x: usize, y: usize } #[derive(Clone, Copy)] struct TerminalCharacter { character: char, styles: CharacterStyles } }
Row 的预分配
数据解析器的是应用中被优化最频繁的部分,其中很多改动超出了本文的范畴。在此我们列举提升最大的几个优化。
以下是 Row 的定义,其中添加字符的方法是解析器中最常使用的方法。特别是向行尾添加字符,这个过程中会将 TerminalCharacter 添加到 Row 的 columns 字段。每次 push 都会改变这个 vector 的大小,并可能造成内存的再分配。这对性能造成了一定的影响。为此我们在新建或者调整窗体大小的时候,对 Row 进行了预分配。
代码修改前:
#![allow(unused)] fn main() { impl Row { pub fn new() -> Self { Row { columns: Vec::new(), } }} } }
修改后:
#![allow(unused)] fn main() { impl Row { pub fn new(width: usize) -> Self { Row { columns: Vec::with_capacity(width), } }} } }
具体代码可以参考该链接。
缓存字符长度
有些字符比另一些更长,例如东亚的字符,或者 emoji。 Zellij 使用了 unicode-width 这个优秀的 crate,去查询字符的长度。
在将字符加入行中后,虚拟终端需要知道当前行的长度,去决定是否要自动换行。因此我们需要不停地查询字符的长度。
既然我们要多次查询字符的长度,我们可以缓存 c.width() 的结果,将其存入 TerminalCharacter 结构体中。
于是如下程序:
#![allow(unused)] fn main() { #[derive(Clone, Copy)] struct TerminalCharacter { character: char, styles: CharacterStyles } impl Row { pub fn width(&self) -> usize { let mut width = 0; for terminal_character in self.columns.iter() { width += terminal_character.character.width(); } width } } }
在做了如下更改后,性能得到了提升:
#![allow(unused)] fn main() { #[derive(Clone, Copy)] struct TerminalCharacter { character: char, styles: CharacterStyles, width: usize, } impl Row { pub fn width(&self) -> usize { let mut width = 0; for terminal_character in self.columns.iter() { width += terminal_character.width; } width } } }
实际代码可以参考该链接。
加速渲染
Screen 线程的渲染部分将每个窗格的状态,按照前文提到的数据结构进行组织,并将其转换成 ANSI/VT 指令,发送到用户的虚拟终端上。
Grid 中的 render 方法将各个字符以及它的样式和位置转换成 ANSI/VT 指令并发给终端,覆盖前一次渲染的结果。
#![allow(unused)] fn main() { fn render(&mut self) -> String { let mut vte_output = String::new(); let mut character_styles = CharacterStyles::new(); let x = self.get_x(); let y = self.get_y(); for (line_index, line) in grid.viewport.iter().enumerate() { vte_output.push_str( // goto row/col and reset styles &format!("\u{1b}[{};{}H\u{1b}[m", y + line_index + 1, x + 1) ); for (col, t_character) in line.iter().enumerate() { let styles_diff = character_styles .update_and_return_diff(&t_character.styles); if let Some(new_styles) = styles_diff { // if this character's styles are different // from the previous, we update the diff here vte_output.push_str(&new_styles); } vte_output.push(t_character.character); } // we clear the character styles after each line // in order not to leak styles from the pane to our left character_styles.clear(); } vte_output } }
具体代码可以参考该链接。
写入 STDOUT 是一个很耗时的操作,我们可以通过限制发往终端的指令数量,从而提升应用的性能。为了达成这个目的,我们要采用一个输出缓冲区,用于追踪渲染时改变的视图区域。在渲染时,就可以构造这部分区域的指令。
#![allow(unused)] fn main() { #[derive(Debug)] pub struct CharacterChunk { pub terminal_characters: Vec<TerminalCharacter>, pub x: usize, pub y: usize, } #[derive(Clone, Debug)] pub struct OutputBuffer { changed_lines: Vec<usize>, // line index should_update_all_lines: bool, } impl OutputBuffer { pub fn update_line(&mut self, line_index: usize) { self.changed_lines.push(line_index); } pub fn clear(&mut self) { self.changed_lines.clear(); } pub fn changed_chunks_in_viewport( &self, viewport: &[Row], ) -> Vec<CharacterChunk> { let mut line_changes = self.changed_lines.to_vec(); line_changes.sort_unstable(); line_changes.dedup(); let mut changed_chunks = Vec::with_capacity(line_changes.len()); for line_index in line_changes { let mut terminal_characters: Vec<TerminalCharacter> = viewport .get(line_index).unwrap().columns .iter() .copied() .collect(); changed_chunks.push(CharacterChunk { x: 0, y: line_index, terminal_characters, }); } changed_chunks } }} }
实际代码可以参考该链接。
当前的实现仅仅跟踪了改动行,也尝试过对列做进一步的优化,但我发现这样会极大增加代码的复杂度,但对性能的提升十分有限。
最后,我们来看看所有这些优化的成效。以下是使用 hyperfine --show-output "cat /tmp/bigfile" 的结果,窗体大小还是 59 行,104 列):
# Zellij before all fixes
Time (mean ± σ): 19.175 s ± 0.347 s [User: 4.5 ms, System: 2754.7 ms]
Range (min … max): 18.647 s … 19.803 s 10 runs
# Zellij after the first fix
Time (mean ± σ): 9.658 s ± 0.095 s [User: 2.2 ms, System: 2426.2 ms]
Range (min … max): 9.433 s … 9.761 s 10 runs
# Zellij after the second fix (includes both fixes)
Time (mean ± σ): 5.270 s ± 0.027 s [User: 2.6 ms, System: 2388.7 ms]
Range (min … max): 5.220 s … 5.299 s 10 runs
# Tmux
Time (mean ± σ): 5.593 s ± 0.055 s [User: 1.3 ms, System: 2260.6 ms]
Range (min … max): 5.526 s … 5.678 s 10 runs
至此,我们的应用已经能在性能上与其他成熟的终端复用软件一较高下。改进的空间依然还有,但现在也能为用户带来优秀的体验了。
结论
我们通过 cat 大文件来度量性能,能覆盖的情景其实比较有限。在其他情境下,Zellij 有可能表现地更好或者更糟。性能测试是一个很复杂的领域,本文的数据只能作为一个模糊的指标。
Zellij 从未宣称比同类应用更快,只是将性能作为一个尽力提高的目标。
如果你发现了本文中的错误,可以联系 aram@poor.dev,我们欢迎任何任何改动、想法、反馈。
如果你觉得本文不错,想在未来看到更多这样的内容,可以考虑在 twitter 上关注我。
链接
致谢
- Tamás Kovács: MPSC 通道和背压等改动的作者,审阅了本文
- Kunal Mohan: 校验并帮助完成了背压相关改动,审阅了本文
- Aram Drevekenin: 参与了数据解析与渲染的改动