Rust 内存错误调试和动态分析工具分享
作者: 吴翱翔 / 后期编辑: 张汉东
相比静态分析工具例如 clippy/ra,动态分析工具则需要程序运行才能进行分析,例如官方的 bench, test
为什么需要动态分析
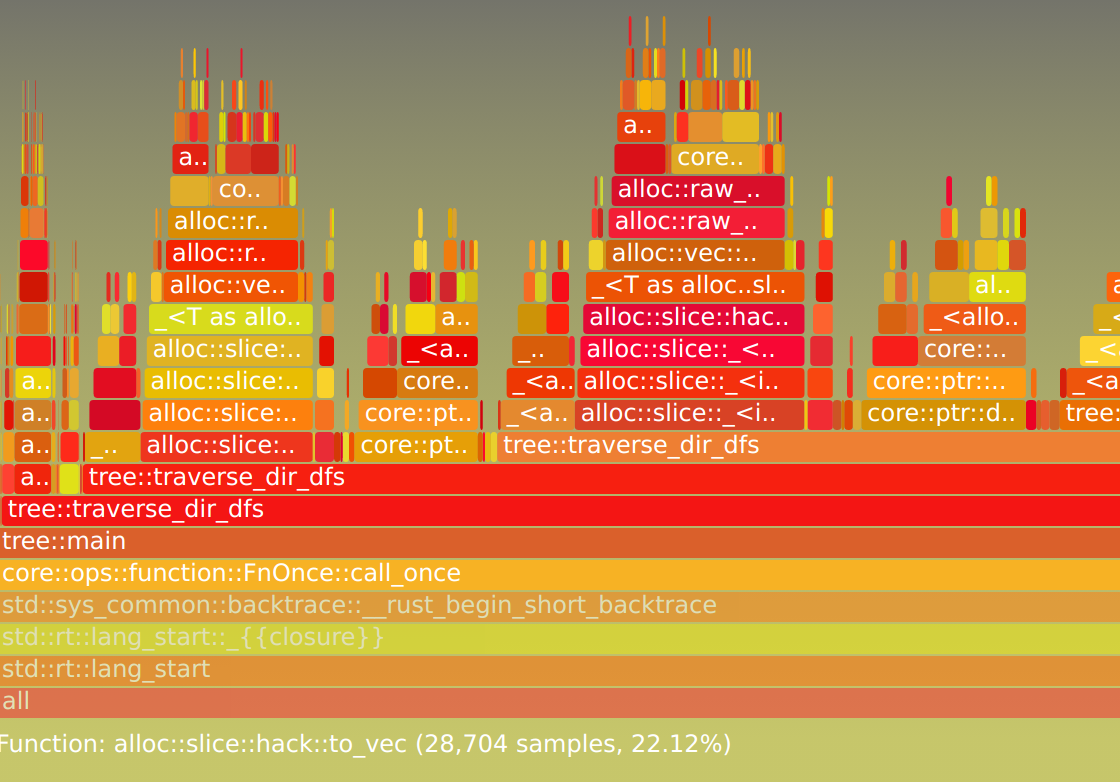
以上是某个 Rust 程序动态分析生成的火焰图,通过火焰图可以很清晰的看到程序的性能瓶颈在频繁 alloc 分配内存
借助动态分析不仅能发现程序性能瓶颈,还能调试运行时的内存错误,也可以生成函数调用树让团队新成员能快速读懂项目代码
目录 - 动态分析工具
- 常用调试工具和内存检测工具: 首先通过一个 segfault 案例,介绍常用调试工具如何检测该案例的内存错误:
- coredumpctl
- valgrind
- gdb
- lldb/vscode-lldb/Intellij-Rust
- 火焰图/函数调用树等动态分析工具(profile)
- dmesg
- cargo-miri
- pref
- cargo-flamegraph
- KCachegrind
- gprof
- uftrace
- ebpf
- 最后通过上述工具再分析几个内存错误案例:
- SIGABRT/double-free
- SIGABRT/free-dylib-mem
segfault 案例和常用调试工具
以下是我重写 ls 命令的部分源码(以下简称ls 应用),完整源码在这个代码仓库
fn main() { let dir = unsafe { libc::opendir(input_filename.as_ptr().cast()) }; loop { let dir_entry = unsafe { libc::readdir(dir) }; if dir_entry.is_null() { break; } // ... } }
跟原版 ls 命令一样,输入参数是一个文件夹时能列出文件夹内所有文件名
但当 ls 应用的参数不是文件夹时,就会 segfault 内存段错误:
> cargo r --bin ls -- Cargo.toml
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/ls Cargo.toml`
Segmentation fault (core dumped)
coredumpctl
systemd-coredump 配置
首先查看系统配置文件 /proc/config.gz 看看是否已开启 coredump 记录功能
> zcat /proc/config.gz | grep CONFIG_COREDUMP
CONFIG_COREDUMP=y
由于 /proc/config.gz 是 gzip 二进制格式而非文本格式,所以要用 zcat 而非 cat 去打印
再看修改 coredumpctl 配置文件 /etc/systemd/coredump.conf
把默认的 coredump 日志大小限制调到 20G 以上: ExternalSizeMax=20G
然后重启: sudo systemctl restart systemd-coredump
查看最后一条 coredump 记录
通过 coredumpctl list 找到最后一条 coredump 记录,也就是刚刚发生的 segfault 错误记录
Tue 2021-07-06 11:20:43 CST 358976 1000 1001 SIGSEGV present /home/w/repos/my_repos/linux_commands_rewritten_in_rust/target/debug/ls 30.6K
注意用户 id 1000 前面的 358976 表示进程的 PID,用作 coredumpctl info 查询
coredumpctl info 358976
PID: 358976 (segfault_opendi)
// ...
Command Line: ./target/debug/ls
// ...
Storage: /var/lib/systemd/coredump/core.segfault_opendi.1000.d464328302f146f99ed984edc6503ca0.358976.1625541643000000.zst (present)
// ...
也可以选择用 gdb 解析 segfault 的 coredump 文件:
coredumpctl gdb 358976 或者 coredumpctl debug 358976
参考: core dump - wiki
valgrind 检查内存错误
valgrind --leak-check=full ./target/debug/ls
// ...
==356638== Process terminating with default action of signal 11 (SIGSEGV): dumping core
==356638== Access not within mapped region at address 0x4
==356638== at 0x497D904: readdir (in /usr/lib/libc-2.33.so)
==356638== by 0x11B64D: ls::main (ls.rs:15)
// ...
gdb 调试分析错误原因
§ gdb 打开 ls 应用的可执行文件:
gdb ./target/debug/ls
§ gdb 通过 l 或 list 命令打印可执行文件的代码:
(gdb) l
§ gdb运行 ls 应用且传入 Cargo.toml 文件名作为入参:
(gdb) run Cargo.toml
Starting program: /home/w/repos/my_repos/linux_commands_rewritten_in_rust/target/debug/ls Cargo.toml
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/usr/lib/libthread_db.so.1".
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff7e5a904 in readdir64 () from /usr/lib/libc.so.6
§ 查看 segfault 发生时的栈帧
(gdb) backtrace
#0 0x00007ffff7e5a904 in readdir64 () from /usr/lib/libc.so.6
#1 0x0000555555568952 in ls::main () at src/bin/ls.rs:15
此时已经找到出问题的系统调用函数是 readdir64,上一个栈帧在 ls.rs 的 15 行
$ 查看问题代码的附近几行
(gdb) list 15
§ 查看问题栈帧的局部变量
info variables能打印全局或 static 变量info locals打印当前栈帧的局部变量info args打印当前栈帧的入参
(gdb) frame 1 # select frame 1
(gdb) info locals
(gdb) frame 1
#1 0x0000555555569317 in ls::main () at src/bin/ls.rs:20
20 let dir_entry = unsafe { libc::readdir(dir) };
(gdb) info locals
dir = 0x0
// ...
此时发现 main 栈帧的 dir = 0x0 是空指针,导致 readdir 系统调用 segfault
分析错误原因
#![allow(unused)] fn main() { let dir = unsafe { libc::opendir(input_filename.as_ptr().cast()) }; loop { let dir_entry = unsafe { libc::readdir(dir) }; // ... } }
问题出在没有判断 opendir 系统调用是否成功,系统调用失败要么返回 NULL 要么返回 -1
如果 opendir 系统调用传入的文件类型不是 directory,就会调用失败
因此 Bug 解决方法是 检查上游的 opendir 创建的 dir 变量是否为 NULL
解决 segfault
只需要在加上 dir 是否为 NULL 的代码,如果为 NULL 则打印系统调用的错误信息
#![allow(unused)] fn main() { if dir.is_null() { unsafe { libc::perror(input_filename.as_ptr().cast()); } return; } }
再次测试 ls 应用读取非文件夹类型的文件
> cargo r --bin ls -- Cargo.toml
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/ls Cargo.toml`
Cargo.toml: Not a directory
此时程序没有发生段错误,并且打印了错误信息 Cargo.toml: Not a directory
关于修复 ls 应用 segfault 的代码改动在这个 commit
参考 gnu.org 的官方教程: https://www.gnu.org/software/gcc/bugs/segfault.html
lldb 调试
lldb 调试和 gdb 几乎一样,只是个别命令不同
(lldb) thread backtrace # gdb is
backtrace
error: need to add support for DW_TAG_base_type '()' encoded with DW_ATE = 0x7, bit_size = 0
* thread #1, name = 'ls', stop reason = signal SIGSEGV: invalid address (fault address: 0x4)
* frame #0: 0x00007ffff7e5a904 libc.so.6`readdir + 52
frame #1: 0x0000555555568952 ls`ls::main::h5885f3e1b9feb06f at ls.rs:15:34
// ...
(lldb) frame select 1 # gdb is
frame 1
frame #1: 0x0000555555569317 ls`ls::main::h5885f3e1b9feb06f at ls.rs:15:34
12
13 let dir = unsafe { libc::opendir(input_filename.as_ptr().cast()) };
14 loop {
-> 15 let dir_entry = unsafe { libc::readdir(dir) };
16 if dir_entry.is_null() {
17 // directory_entries iterator end
18 break;
§ lldb 变量打印上 frame variable 等于 gdb 的 info args 加上 info locals
(gdb) info args 等于 (lldb) frame variable --no-args
除了 primitive types, lldb 还可以打印 String 类型变量的值,但是无法得知 Vec<String> 类型变量的值
vscode-lldb 调试
不打任何断点运行程序时,会指向以下代码
7FFFF7E5A904: 0F B1 57 04 cmpxchgl %edx, 0x4(%rdi)
此时应当关注 vscode 左侧 Debug 侧边栏的 CALL STACK 菜单 (也就 gdb backtrace)
call stack 菜单会告诉 readdir 当前汇编代码的上一帧(也就是 backtrace 第二个栈帧)是 main 函数的 15 行
点击 main 栈帧,相当于 (gdb) frame 1,就能跳转到出问题的源码所在行了
在 main 栈帧 下再通过 variable 菜单发现 readdir 传入的 dir 变量值为 NULL 导致段错误
Intellij-Rust 调试
Debug 运行直接能跳转到问题代码的所在行,并提示 libc::readdir(dir) 的 dir 变量的值为 NULL
动态分析工具
dmesg 查看 segfault 记录
sudo dmesg 能查看最近几十条内核消息,发生 segfault 后能看到这样的消息:
[73815.701427] ls[165042]: segfault at 4 ip 00007fafe9bb5904 sp 00007ffd78ff8510 error 6 in libc-2.33.so[7fafe9b14000+14b000]
cargo-miri 检查 unsafe 代码
可惜 miri 现在似乎还不支持 FFI 调用函数的检查
[w@ww linux_commands_rewritten_in_rust]$ cargo miri run --example sigabrt_free_dylib_data
Compiling linux_commands_rewritten_in_rust v0.1.0 (/home/w/repos/my_repos/linux_commands_rewritten_in_rust)
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `/home/w/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/bin/cargo-miri target/miri/x86_64-unknown-linux-gnu/debug/examples/sigabrt_free_dylib_data`
error: unsupported operation: can't call foreign function: sqlite3_libversion
--> examples/sigabrt_free_dylib_data.rs:5:19
|
5 | let ptr = sqlite3_libversion() as *mut i8;
| ^^^^^^^^^^^^^^^^^^^^ can't call foreign function: sqlite3_libversion
perf 函数调用树
检查 perf 配置
首先通过 perf record 测试下 perf 的配置能否读取系统事件,如果返回 Error 则修改以下配置文件
sudo vim /etc/sysctl.d/sysctl.conf
在 sysctl.conf 配置文件下加上一行:
kernel.perf_event_paranoid = -1
然后重启 sysctl 进程重新加载配置:
sudo systemctl restart systemd-sysctl.service
perf call-graph
用 perf-record 记录 Rust 程序的调用信息:
perf record -a --call-graph dwarf ./target/debug/tree
Rust 程序运行结束后,会在当前目录生成 perf.data 数据文件
perf-report 会默认打开当前目录的 perf.data 文件,也可以通过 -i 参数制定数据文件
用 perf-report 解析 Rust 程序的函数调用树,会进入一个用 curses 写的类似 htop 的命令行 UI 界面:
perf report --call-graph
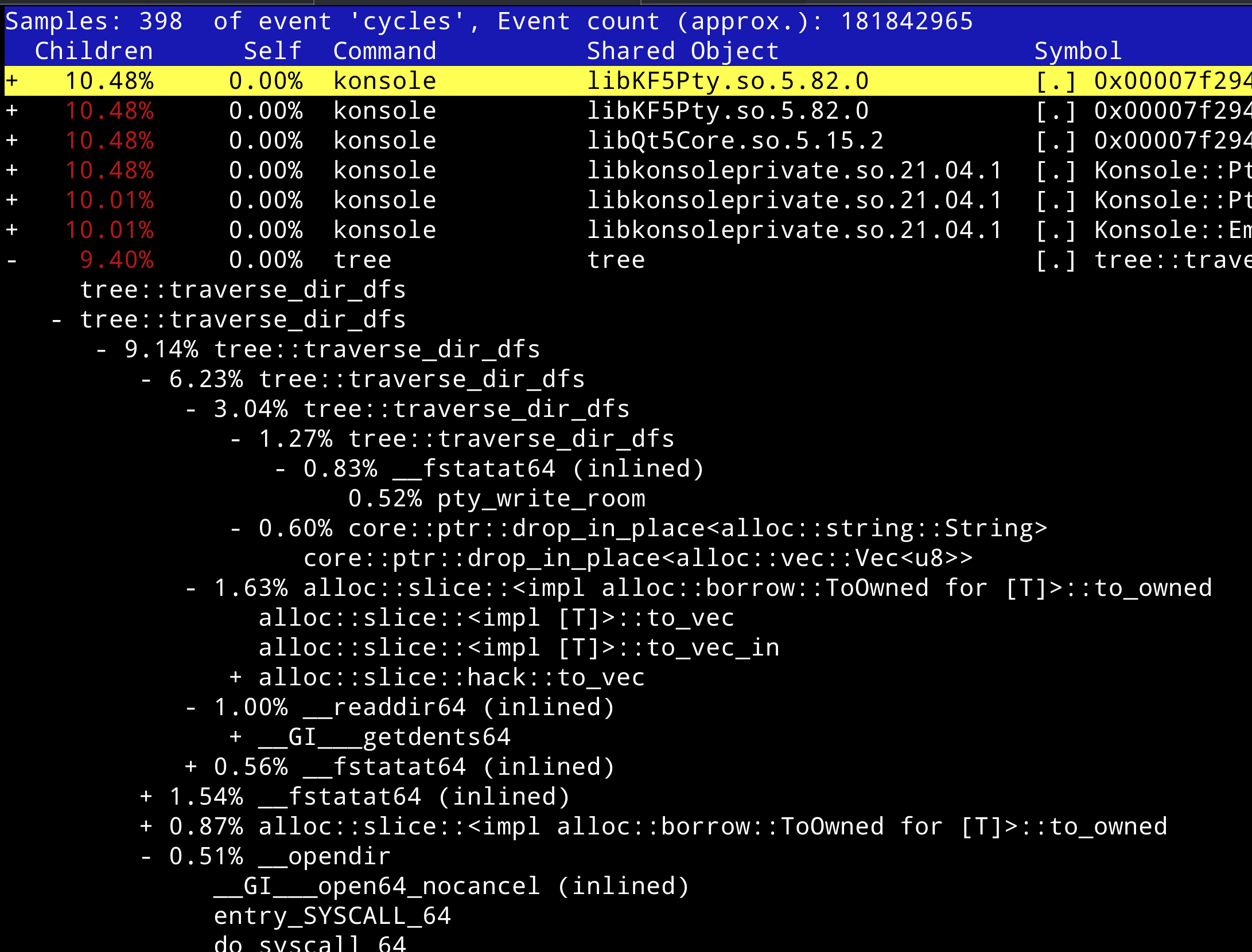
可以选中 tree::main 的函数符号按下回车,选择 zoom into tree thread 来展示 main 函数的子函数调用树
主要浏览方法是通过上下左右方向键移动光标,再通过**+**按键展开或折叠光标所在行的函数调用树
在作者的电脑上,Clion 默认的 profiler(性能探测器)就用的 perf
cargo-flamegraph
cargo-flamegraph 需要系统已装 perf ,能将 perf 数据渲染成火焰图
KCachegrind
valgrind --tool=callgrind ./target/debug/tree
通过 valgrind 生成 callgrind.out.887505 数据( 887505 是 PID ),再通过 KCachegrind 打开进行可视化
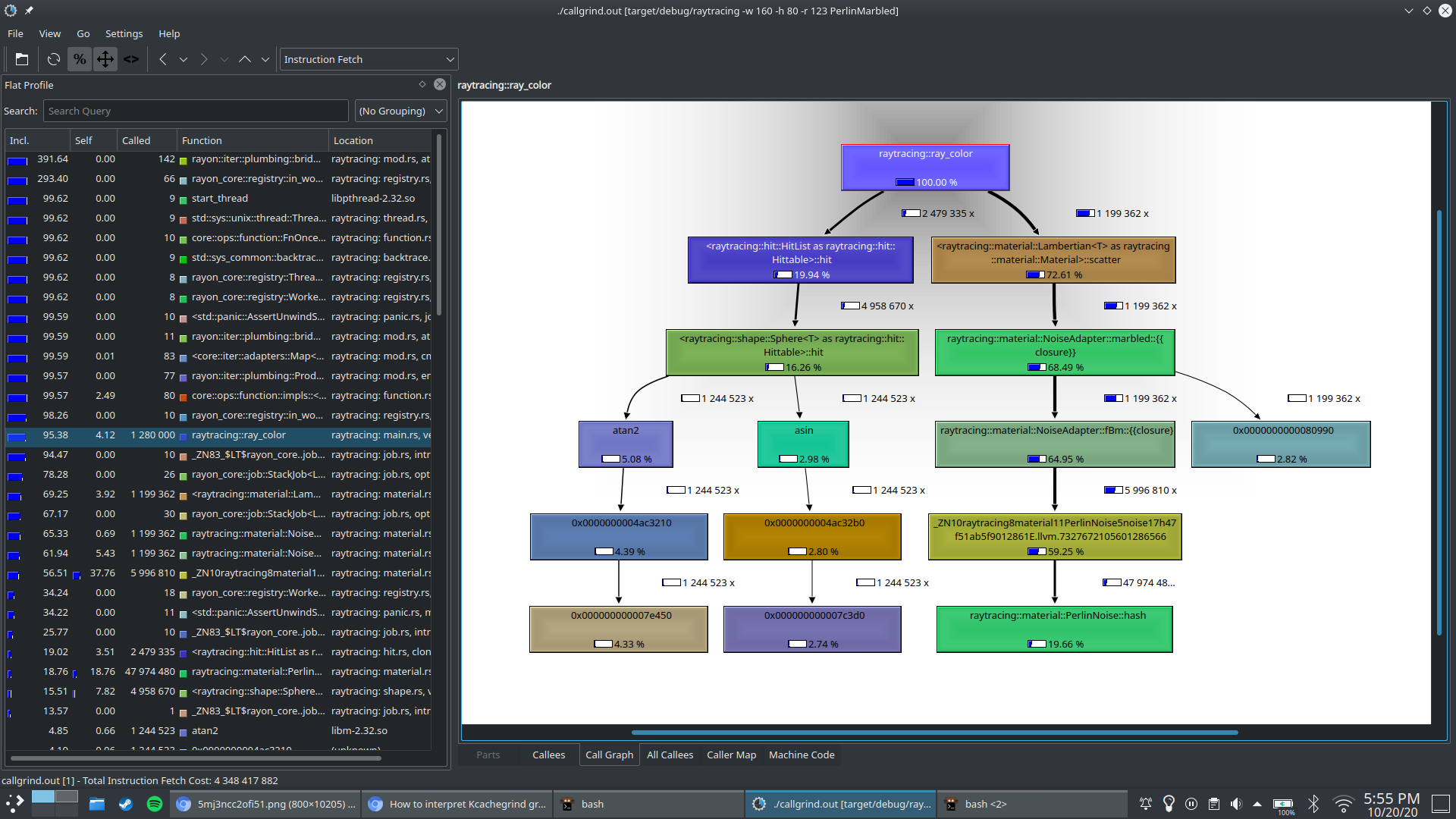
参考: https://users.rust-lang.org/t/is-it-possible-to-print-the-callgraph-of-a-cargo-workspace/50369/6
gprof
gcc/clang 加上 -pg 参数,会在运行程序结束后生成监控数据文件 mon.out
然后 gprof 对 mon.out 文件进行分析,可惜 Rust 没有部分支持
uftrace
为了支持数据通过火焰图格式可视化,安装 utftrace 的同时也把火焰图装了:
yay -S uftrace-git flamegraph-git
跟 grpof/KCachegrind 类似,也是要收集数据,数据可视化分两步走
首先 Rust 编译程序时要加上类似 gcc 的 -pg 的参数:
rustc -g -Z instrument-mcount main.rs
或者用 gccrs 或 gcc 后端进行编译
gccrs -g -pg main.rs
然后 uftrace 开始记录数据:
uftrace record ./main
本文篇幅有限只介绍 uftrace 通过火焰图进行可视化的方式:
uftrace dump --flame-graph | flamegraph > ~/temp/uftrace_flamegraph.svg && google-chrome-stable ~/temp/uftrace_flamegraph.svg
uftrace 记录参数:
- --no-libcall: uftrace 可以加上 --no-libcall 参数不记录系统调用
- --nest-libcall: 例如 new() 函数记录上内置的 malloc()
- --kernel(need sudo): trace kernel function
- --no-event: 不记录线程调度
ebpf
ebpf 分析 Rust 程序应该是可行的,作者还没试过
熟悉上述工具后,可以接下来看几个内存错误的案例
SIGABRT/double-free 案例分享
以下是 tree 命令深度优先搜索遍历文件夹的代码(省略部分无关代码,完整源码链接在这)
#![allow(unused)] fn main() { unsafe fn traverse_dir_dfs(dirp: *mut libc::DIR, indent: usize) { loop { let dir_entry = libc::readdir(dirp); if dir_entry.is_null() { let _sigabrt_line = std::env::current_dir().unwrap(); return; } // ... if is_dir { let dirp_inner_dir = libc::opendir(filename_cstr); libc::chdir(filename_cstr); traverse_dir_dfs(dirp_inner_dir, indent + 4); libc::chdir("..\0".as_ptr().cast()); libc::closedir(dirp); } } } }
这段代码运行时会报错:
malloc(): unsorted double linked list corrupted
Process finished with exit code 134 (interrupted by signal 6: SIGABRT)
通过 gdb 调试能知道 std::env::current_dir() 调用报错了,但错误原因未知
经验: SIGABRT 可能原因
通过上述段错误的分析,我们知道 SIGSEGV 可能的原因是例如 readdir(NULL) 解引用空指针
根据作者开发经验,SIGABRT 的可能原因是 double free
valgrind 检查 double free
顺着 double-free 的思路,通过 valgrind 内存检查发现,libc::closedir(dirp) 出现 InvalidFree/DoubleFree 的内存问题
分析 double free 原因
再细看源码,递归调用前创建的是子文件夹的指针,递归回溯时却把当前文件夹指针给 close 掉了
这就意味着,一旦某个目录有 2 个以上的子文件夹,那么当前的文件夹指针可能会被 free 两次
进而将问题的规模简化成成以下三行代码:
#![allow(unused)] fn main() { let dirp = libc::opendir("/home\0".as_ptr().cast()); libc::closedir(dirp); libc::closedir(dirp); }
double free 的通用解决方法
C 语言编程习惯: free 某个指针后必须把指针设为 NULL
#![allow(unused)] fn main() { let mut dirp = libc::opendir("/home\0".as_ptr().cast()); libc::closedir(dirp); dirp = std::ptr::null_mut(); libc::closedir(dirp); dirp = std::ptr::null_mut(); }
在「单线程应用」中,这种解决方法是可行的,
第一次 free 后 dirp 指针被成 NULL,第二次 free 时传入 dirp 则什么事都不会发生
因为大部分的 C/Java 函数第一行都会判断输入是否空指针 if (ptr == null) return
为什么有时 double free 没报错
有个问题困惑了我:
- 为什么连续写几行 closedir 进程会提前 SIGABRT?
- 为什么循环中多次 closedir 进程还能正常退出?
- 为什么循环中多次 closedir 调用
std::env::current_dir()时就 SIGABRT?
原因是 double free 不一定能及时被发现,可能立即让进程异常中止,也可能要等下次 malloc 时才会报错
正因为 current_dir() 用了 Vec 申请堆内存,内存分配器发现进程内存已经 corrupted 掉了所以中止进程
我摘抄了一些系统编程书籍对这一现象的解释:
one reason malloc failed is the memory structures have been corrupted, When this happens, the program may not terminate immediately
感兴趣的读者可以看这本书: Beginning Linux Programming 4th edition 的 260 页
SIGABRT/free-dylib-mem 案例分享
假设我想打印 sqlite 的版本,sqlite 版本信息以静态字符串的形式存储在 /usr/lib/libsqlite3.so
#[link(name = "sqlite3")] extern "C" { pub fn sqlite3_libversion() -> *const libc::c_char; } fn main() { unsafe { let ptr = sqlite3_libversion() as *mut i8; let version = String::from_raw_parts(ptr.cast(), "3.23.0\0".len(), "3.23.0\0".len()); println!("found sqlite3 version={}", version); } }
结果上述代码一运行就发生内存错误 SIGABRT 异常中止,通过 gdb 调试发现报错前一个栈帧在 unsafe 代码块的析构流程内
由于代码中只有 version 是 String 类型需要调用 drop 自动析构,所以就把问题锁定在 String 的析构错误上
根据操作系统进程内存管理相关知识,当 Rust 的进程想要释放不属于 Rust 进程而是属于 libsqlite3.so 动态链接库的内存时就会 SIGABRT
解决方法是通过 std::mem::forget 阻止 String 的析构函数调用,这也是 mem::forget API 最常用的应用场景
更多的内存错误调试案例
可以关注作者的 linux_commands_rewritten_in_rust 项目的 src/examples 文件夹
examples 目录下几乎都是各种内存错误的常见例子,也是作者踩过坑的各种内存 Bug
项目链接: <https://github.com/pymongo/linux_commands_rewritten_in_rust/>