Rbatis ORM 2.0 | 零开销编译时动态SQL的探索
作者:朱秀杰
- 什么是动态SQL?
在某种高级语言中,如果嵌入了SQL语句,而这个SQL语句的主体结构已经明确,例如在Java的一段代码中有一个待执行的SQL“select * from t1 where c1>5”,在Java编译阶段,就可以将这段SQL交给数据库管理系统去分析,数据库软件可以对这段SQL进行语法解析,生成数据库方面的可执行代码,这样的SQL称为静态SQL,即在编译阶段就可以确定数据库要做什么事情。 而如果嵌入的SQL没有明确给出,如在Java中定义了一个字符串类型的变量sql:String sql;,然后采用preparedStatement对象的execute方法去执行这个sql,该sql的值可能等于从文本框中读取的一个SQL或者从键盘输入的SQL,但具体是什么,在编译时无法确定,只有等到程序运行起来,在执行的过程中才能确定,这种SQL叫做动态SQL
前言
笔者曾经在2020年发布基于rust的orm第一版,参见文章https://rustcc.cn/article?id=1f29044e-247b-441e-83f0-4eb86e88282c
v1.8版本依靠rust提供的高性能,sql驱动依赖sqlx-core,未作特殊优化性能即超过了go、java之类的orm v1.8版本一经发布,受到了许多网友的肯定和采纳,并应用于诸多生产系统之上。 v1.8版本借鉴了mybatis plus 同时具备的基本的crud功能并且推出py_sql简化组织编写sql的心理压力,同时增加一系列常用插件,极大的方便了广大网友。
同时1.8版本也具备了某些网友提出的问题,例如:
- by_id*()的方式,局限性很大,只能操作具有该id的表,能否更改为 by_column*(column:&str,arg:xxx);传入需要操作的column的形式?
- CRUDTable trait 能否不要指定id主键(因为有的表有可能不止一个主键)?
- 当使用TxManager外加tx_id管理事务的方式,因为用到了锁,似乎影响性能
- py_sql使用ast+解释执行的方式,不但存在 运行时,运行时解析阶段,运行时解释执行阶段,能否优化为完全0开销的方式?
- 能否加入xml格式的动态sql存储,实现sql和代码解耦分离,不要使用CDATA转义(太麻烦了),适当兼容从java迁移过来的系统并适当复用之前的mybais xml?
经过一段时间的思考和整理,于是推出v2.0版本,实现完全0开销的动态sql,sql构建性能提高N倍(只生成sql),完整查询QPS(组织sql到得到结果)性能提高至少2倍以上,并解决以上问题
兼顾方便和性能,例如这里使用html_sql查询(v2.0版本)分页代码片段:
- html文件
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "https://github.com/rbatis/rbatis_sql/raw/main/mybatis-3-mapper.dtd">
<mapper>
<select id="select_by_condition">
select * from biz_activity where
<if test="name != ''">
name like #{name}
</if>
</select>
</mapper>
- main.rs文件
#[crud_table] #[derive(Clone, Debug)] pub struct BizActivity { pub id: Option<String>, pub name: Option<String>, pub pc_link: Option<String>, pub h5_link: Option<String>, pub pc_banner_img: Option<String>, pub h5_banner_img: Option<String>, pub sort: Option<String>, pub status: Option<i32>, pub remark: Option<String>, pub create_time: Option<NaiveDateTime>, pub version: Option<i32>, pub delete_flag: Option<i32>, } #[html_sql(rb, "example/example.html")] async fn select_by_condition(rb: &mut RbatisExecutor<'_>, page_req: &PageRequest, name: &str) -> Page<BizActivity> { todo!() } #[async_std::main] pub async fn main() { fast_log::init_log("requests.log", 1000, log::Level::Info, None, true); //use static ref let rb = Rbatis::new(); rb.link("mysql://root:123456@localhost:3306/test") .await .unwrap(); let a = select_by_condition(&mut (&rb).into(), &PageRequest::new(1, 10), "test") .await .unwrap(); println!("{:?}", a); }
介绍Java最普遍的ORM框架前世今生 - Mybatis、MybatisPlus,XML,OGNL表达式,dtd文件
-
MyBatis在java和sql之间提供更灵活的映射方案,MyBatis将sql语句和方法实现,直接写到xml文件中,实现和java程序解耦 为何这样说,MyBatis将接口和SQL映射文件进行分离,相互独立,但又通过反射机制将其进行动态绑定。 其实它底层就是Mapper代理工厂[MapperRegistry]和Mapper标签映射[MapperStatement],它们两个说穿了就是Map容器,就是我们常见的HashMap、ConcurrentHashMap。 所以说,MyBatis使用面向接口的方式这种思想很好的实现了解耦和的方式,同时易于开发者进行定制和扩展,比如我们熟悉的通用Mapper和分页插件pageHelper,方式也非常简单。
-
什么是DTD文件?
文档类型定义(DTD)可定义合法的XML文档构建模块。它使用一系列合法的元素来定义文档的结构。同样,它可以作用于xml文件也可以作用于html文件. Intellij IDEA,CLion,VSCode等等ide均具备该文件合法模块,标签智能提示的能力 例如:
<?xml version="1.0" encoding="UTF-8" ?>
<!ELEMENT mapper (sql* | insert* | update* | delete* | select* )+>
<!ATTLIST mapper
>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "https://github.com/rbatis/rbatis_sql/raw/main/mybatis-3-mapper.dtd">
<mapper>
</mapper>
- 什么是OGNL表达式?
OGNL(Object-Graph Navigation Language)大概可以理解为:对象图形化导航语言。是一种可以方便地操作对象属性的开源表达式语言. Rbatis在html,py_sql内部借鉴部分ognl表达式的设计,但是rbatis实际操作的是json对象。
例如(#{name},表示从参数中获取name参数,#符号表示放如预编译sql参数并替换为mysql的'?'或者pg的‘$1’,如果是$符号表示直接插入并替换sql):
<select id="select_by_condition">select * from table where name like #{name}</select>
探索实现架构走弯路-最初版本基于AST+解释执行
AST抽象语法树,可以参考其他博客 https://blog.csdn.net/weixin_39408343/article/details/95984062
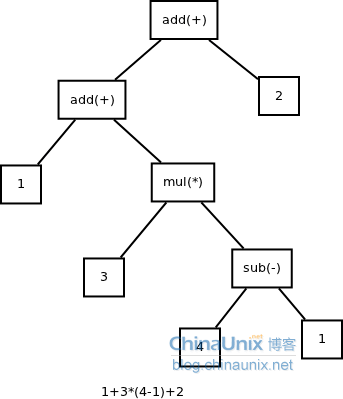
- AST结构体大概长这样
#![allow(unused)] fn main() { #[derive(Clone, Debug, Serialize, Deserialize)] pub struct Node { pub left: Option<Box<Node>>, pub value: Value, pub right: Option<Box<Node>>, pub node_type: NodeType, } impl Node{ #[inline] pub fn eval(&self, env: &Value) -> Result<Value, crate::error::Error> { if self.equal_node_type(&NBinary) { let left_v = self.left.as_ref().unwrap().eval(env)?; let right_v = self.right.as_ref().unwrap().eval(env)?; let token = self.to_string(); return eval(&left_v, &right_v, token); } else if self.equal_node_type(&NArg) { return self.value.access_field(env); } return Result::Ok(self.value.clone()); } } }
表达式是如何运行的?
- 例如执行表达式‘1+1’,首先经过框架解析成3个Node节点的二叉树,‘+’符号节点左叶子节点为1,右叶子节点为1
- 执行时,执行‘+’节点的eval方法,这时它会执行叶子节点的eval()方法得到2给值(这里eval方法实际执行了clone操作),并根据符号‘+’对2给值累加,并返回。
结论: 这种架构下,其实存在一些弊端,例如存在很多不必要的clone操作,node需要在程序运行阶段 解析->生成AST->逐行解释执行AST。这些都是存在一些时间和cpu、内存开销的
探索实现架构走弯路-尝试基于wasm
- 什么是wasm? WebAssembly/wasm WebAssembly 或者 wasm 是一个可移植、体积小、加载快并且兼容 Web 的全新格式。
rust也有一些wasm运行时,这类框架可以进行某些JIT编译优化工作。例如 wasmtime/cranelift/ 曾经发现调用cranelift 运行时调用开销 800ns/op,对于频繁进出宿主-wasm运行时调用的话,似乎并不是特别适合ORM。况且接近800ns的延迟,说实话挺难接受的。参见issues https://github.com/bytecodealliance/wasmtime/issues/2644 经过一些时间等待,该问题被解决后,仍然需要耗费至少50ns的时间开销。对于sql中出现参数动则20次的调用,时间延迟依然会进一步拉大
探索实现架构-真正的0开销抽象,尝试过程宏,是元编程也是高性能的关键
我们一直在说0开销,C++的实现遵循“零开销原则”:如果你不使用某个抽象,就不用为它付出开销[Stroustrup,1994]。而如果你确实需要使用该抽象,可以保证这是开销最小的使用方式。 — Stroustrup
- 如果我们使用过程宏直接把表达式编译为纯rust函数代码,那么就实现了真正意义上令人兴奋的0开销!不但降低cpu使用率,同时提升性能
过程宏框架,syn和quote(分别解析和生成词条流)
我们知道syn和quote结合起来是实现过程宏的主要方式,但是syn和quote仅支持rust语法规范。 如何让它能变相解析我们自定义的语法糖呢?
- 答案就是让我们的语法糖转换为符合rust规范的语法,让syn和quote能够正常解析和生成词条流
关于扩展性-包装serde_json还是拷贝serde_json源码?
我们执行的表达式参数都是json参数,这里涉及使用到serde_json。但是serde_json其实不具备 类似 serde_json::Value + 1 的语法规则,你会得到编译错误!
-
(语法不支持)解决方案: impl std::ops::Add for serde_json::Value{} 实现标准库的接口即可支持。
-
但是碍于 孤儿原则(当你为某类型实现某 trait 的时候,必须要求类型或者 trait 至少有一个是在当前 crate 中定义的。你不能为第三方的类型实现第三方的 trait )你会得到编译错误!
语法糖语义和实现trait 支持扩展
- (孤儿原则)解决方案: 实现自定义结构体,并依赖serde_json::Value对象,并实现该结构体的语法规则支持!
自定义的结构体大概长这样
#![allow(unused)] fn main() { #[derive(Eq, PartialEq, Clone, Debug)] pub struct Value<'a> { pub inner: Cow<'a, serde_json::Value>, } }
性能优化1-写时复制Cow-避免不必要的克隆
- 科普:写时复制(Copy on Write)技术是一种程序中的优化策略,多应用于读多写少的场景。主要思想是创建对象的时候不立即进行复制,而是先引用(借用)原有对象进行大量的读操作,只有进行到少量的写操作的时候,才进行复制操作,将原有对象复制后再写入。这样的好处是在读多写少的场景下,减少了复制操作,提高了性能。
实现表达式执行时,并不是所有操作都存在‘写’的,大部分场景是基于‘读’ 例如表达式:
<if test="id > 0 || id == 1">
id = ${id}
</if>
- 这里,读取id并判断是否大于0或等于1
性能优化2-重复变量利用优化
- 表达式定义了变量参数id,进行2次访问,那我们生成的fn函数中即要判断是否已存在变量id,第二次直接访问而不是重复生成 例如:
<select id="select_by_condition">
select * from table where
id != #{id}
and 1 != #{id}
</select>
性能优化3-sql预编译参数替换算法优化
预编译的sql需要把参数替换为例如 mysql:'?',postgres:'$1'等符号。
- 字符串替换性能的关键-rust的string存储于堆内存
rust的String对象是支持变长的字符串,我们知道Vec是存储于堆内存(因为计算机堆内存容量更大,而栈空间是有限的)大概长这样
#![allow(unused)] fn main() { #[stable(feature = "rust1", since = "1.0.0")] pub struct String { vec: Vec<u8>, } }
-
性能优化-不使用format!宏等生成String结构体的函数,减少访问堆内存。
-
巧用char进行字符串替换,因为单个char存储于栈,栈的速度快于堆
-
替换算法优化内容长这样.(这里我们使用
new_sql.push(char),只访问栈内存空间)
#![allow(unused)] fn main() { macro_rules! push_index { ($n:expr,$new_sql:ident,$index:expr) => { { let mut num=$index/$n; $new_sql.push((num+48) as u8 as char); $index % $n } }; ($index:ident,$new_sql:ident) => { if $index>=0 && $index<10{ $new_sql.push(($index+48)as u8 as char); }else if $index>=10 && $index<100 { let $index = push_index!(10,$new_sql,$index); let $index = push_index!(1,$new_sql,$index); }else if $index>=100 && $index<1000{ let $index = push_index!(100,$new_sql,$index); let $index = push_index!(10,$new_sql,$index); let $index = push_index!(1,$new_sql,$index); }else if $index>=1000 && $index<10000{ let $index = push_index!(1000,$new_sql,$index); let $index = push_index!(100,$new_sql,$index); let $index = push_index!(10,$new_sql,$index); let $index = push_index!(1,$new_sql,$index); }else{ use std::fmt::Write; $new_sql.write_fmt(format_args!("{}", $index)) .expect("a Display implementation returned an error unexpectedly"); } }; } for x in sql.chars() { if x == '\'' || x == '"' { if string_start == true { string_start = false; new_sql.push(x); continue; } string_start = true; new_sql.push(x); continue; } if string_start { new_sql.push(x); } else { if x=='?' && #format_char != '?' { index+=1; new_sql.push(#format_char); push_index!(index,new_sql); }else{ new_sql.push(x); } } } }
最后的验证阶段,(零开销、编译时动态SQL)执行效率压测
#![allow(unused)] fn main() { v2.0请求耗时 耗时:3923900800 耗时:3576816000 耗时:3248177800 耗时:3372922200 v1.8请求耗时 耗时:6372459300 耗时:7709288000 耗时:6739494900 耗时:6590053200 }
结论: v2.0相对于老版本,qps至少快一倍